Engineering data science & AI platforms
Part II: Designing, building and operating data & AI platforms
Attribution & copyright notice
This lecture is based on the following open access materials:
- Voltron Data, The Composable Codex
- Documentation of the following Python libraries:
DuckDB, polars, Ibis, dagster, hamilton, Shiny for Python, marimo
Source code: https://github.com/anthology-of-data-science/lecture-engineering-data-ai-platforms
This work is licensed under CC BY-SA 4.0![]()
![]()
![]()
How to manage
the data science lifecycle in real life?

The best book on data engineering
- Chapter 1: Tradeoffs in Data Systems Architecture
Analytical versus Operational Systems - Cloud versus Self-Hosting - Distributed versus Single-Node Systems - Data Systems, Law, and Society - Chapter 2: Defining Nonfunctional Requirements
Case Study: Social Network Home Timelines- Describing Performance - Reliability and Fault Tolerance - Scalability - Maintainability - Chapter 3: Data Models and Query Languages
Relational Model versus Document Model - Graph-Like Data Models - Event Sourcing and CQRS - DataFrames, Matrices, and Arrays - Chapter 4: Storage and Retrieval
Storage and Indexing for OLTP - Data Storage for Analytics - Multidimensional and Full-Text Indexes - (…)
- Chapter 11: Batch Processing
Batch Processing in Distributed Systems - Batch Processing Models - Batch Use Cases

The common definition of data engineering
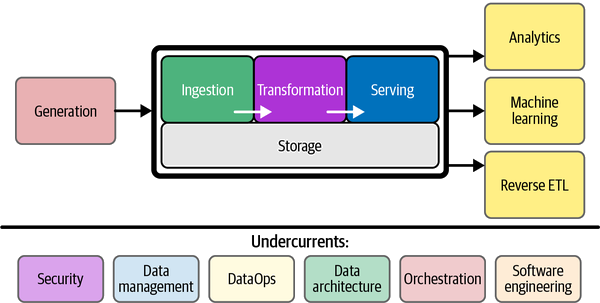
Our dream: a data system that just works
The problem

It all started with the relational database management systems (RDBMS)

What makes a database?
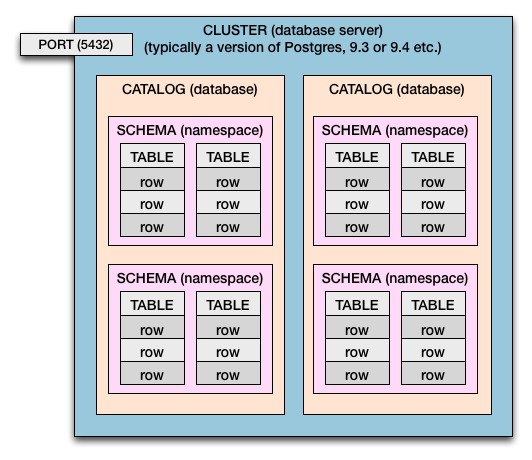
| System | Catalog | Database |
|---|---|---|
| postgresql, mysql, mssql, duckdb | database | schema |
| datafusion, trino | catalog | schema |
| druid | dataSourceType | dataSource |
| bigquery | project | database |
| flink | catalog | database |
| clickhouse | database | |
| clickhouse, impala, mysql, pyspark, snowflake | database |
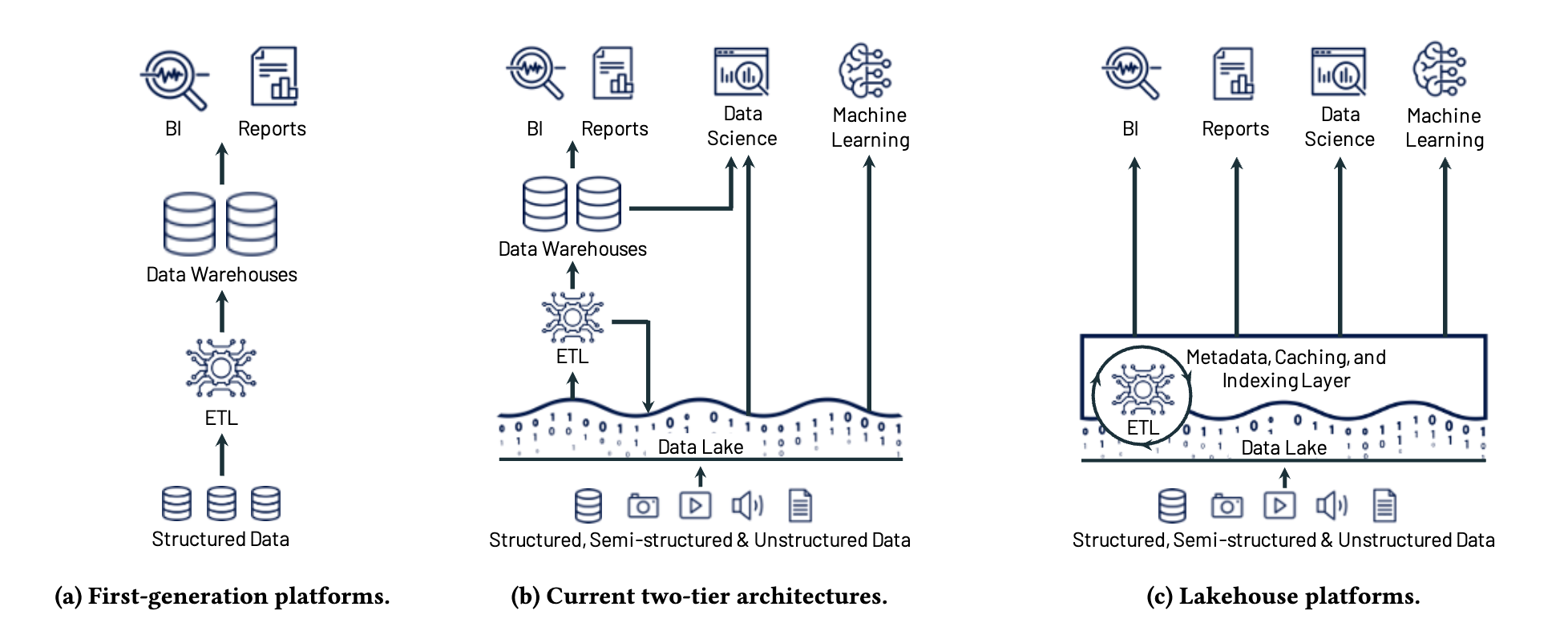
Evolution of analytical system architectures
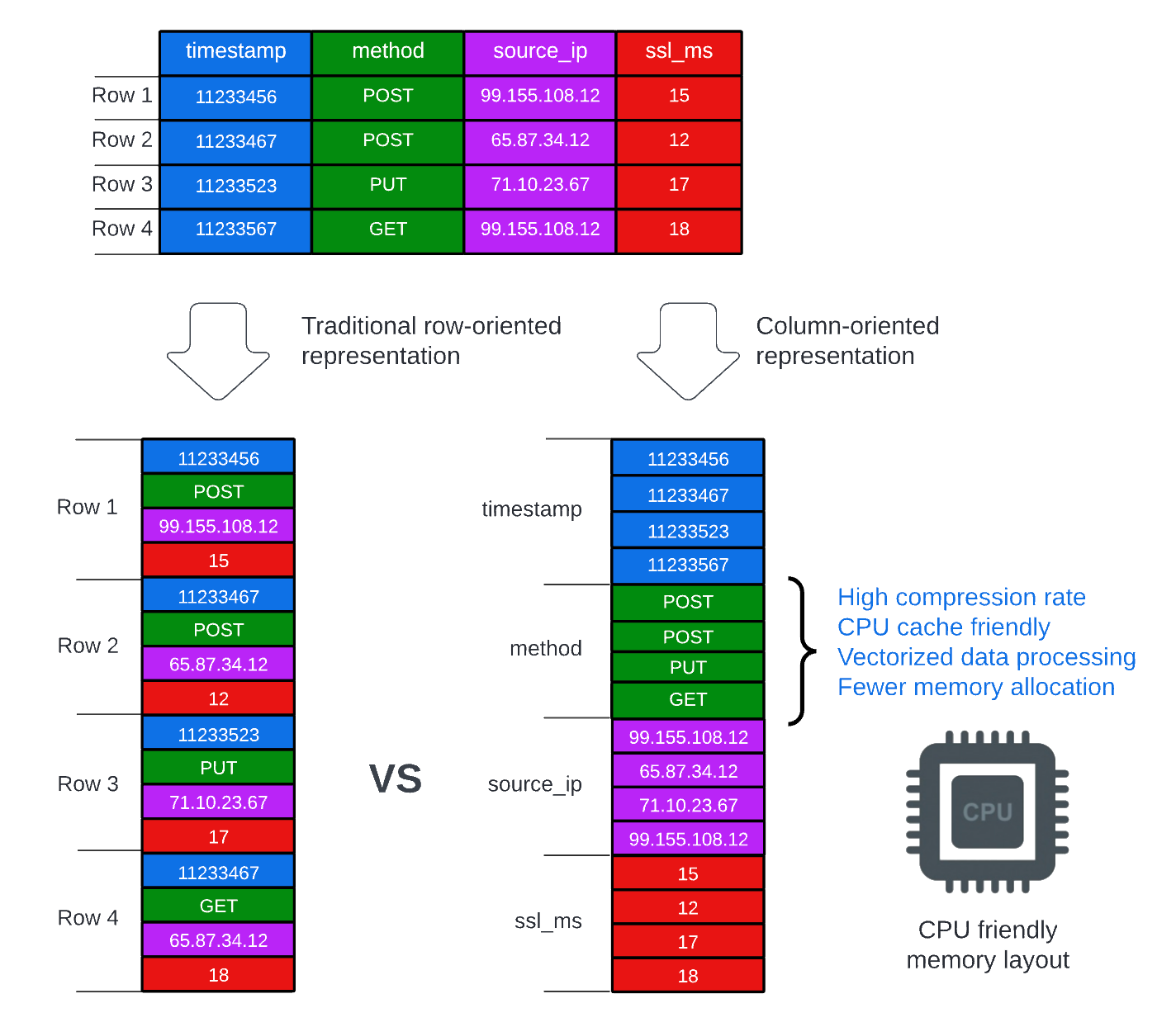
From row-based to column-based systems
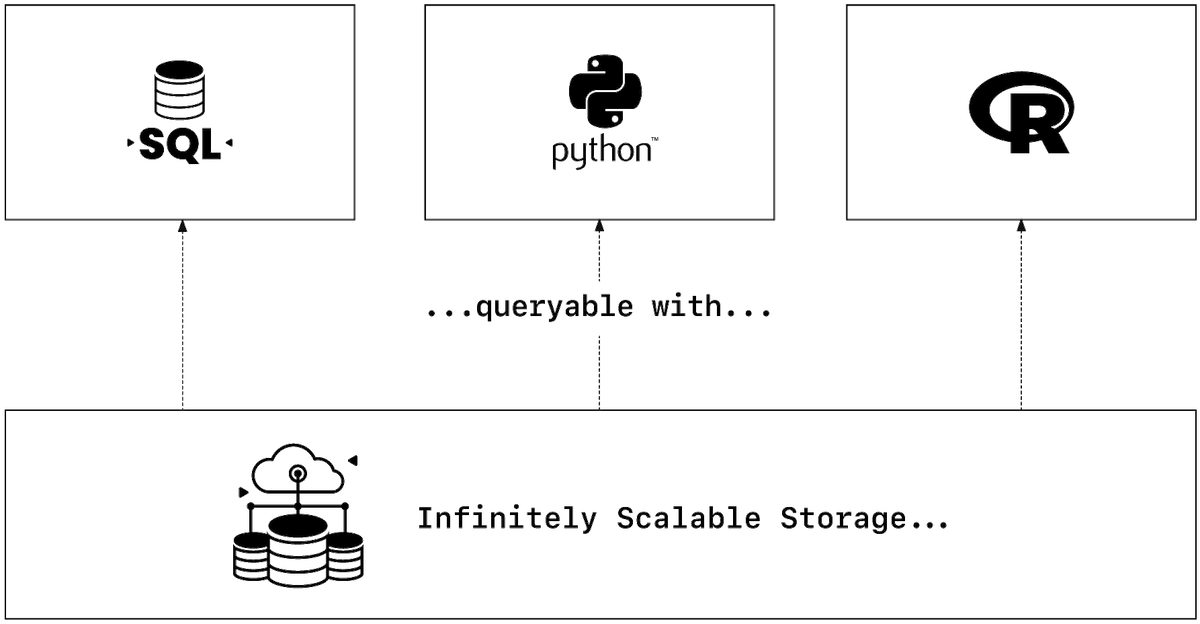
The Composable Data Stack takes the unbundling even further
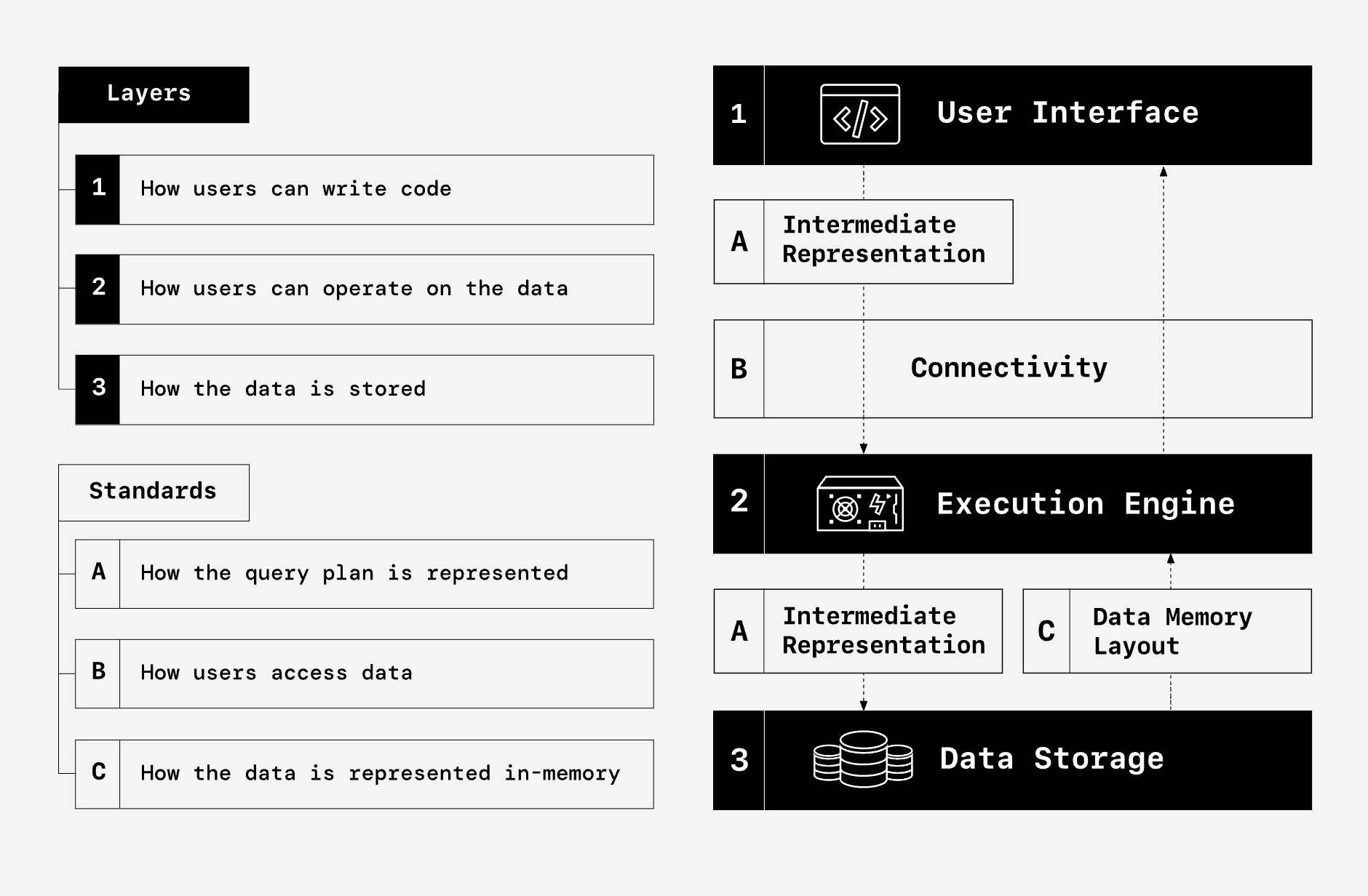
The Composable Data Stack takes the unbundling even further
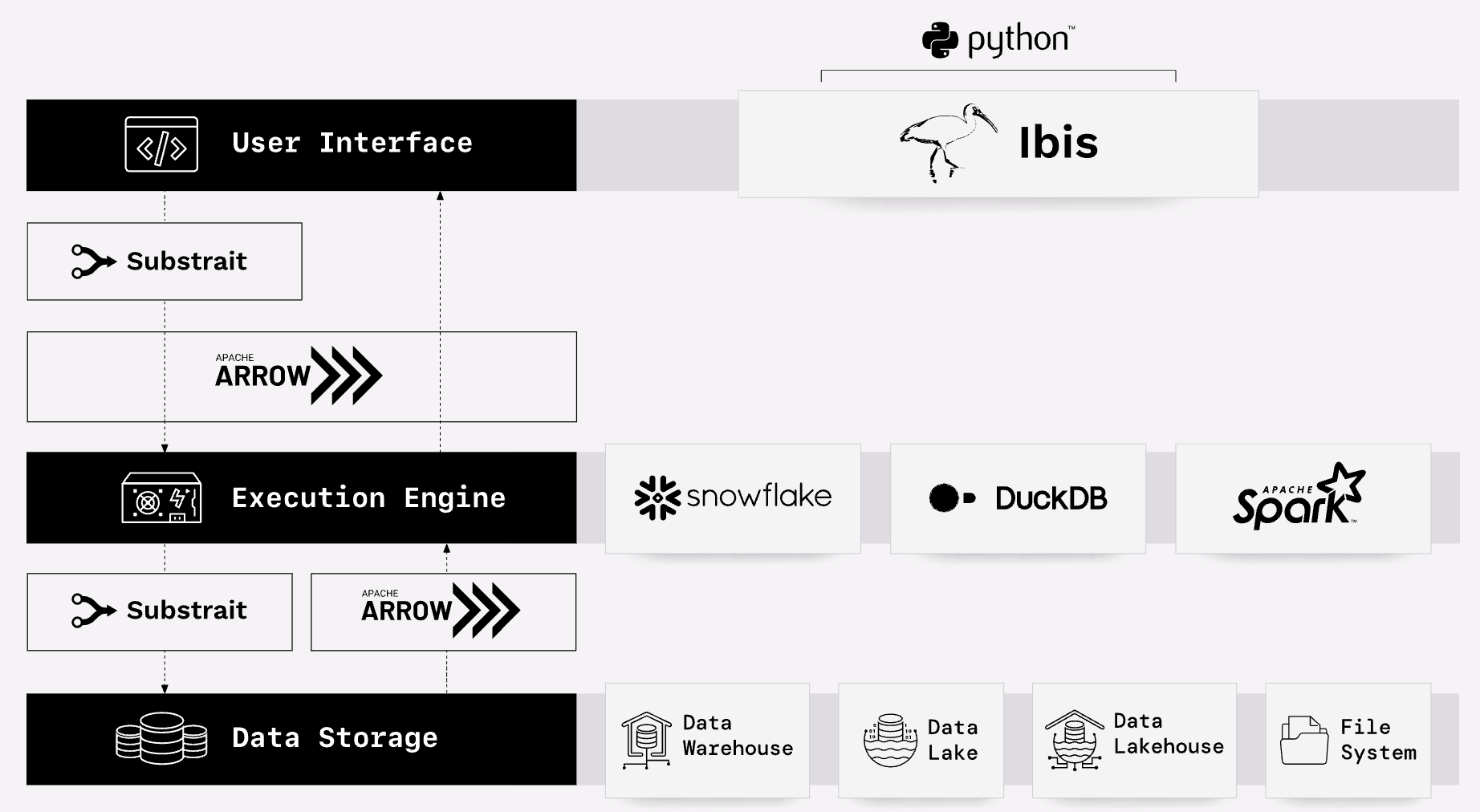
End-to-end columnar data with Apache Arrow ADBC and Flight SQL
From components to a whole platform architecture
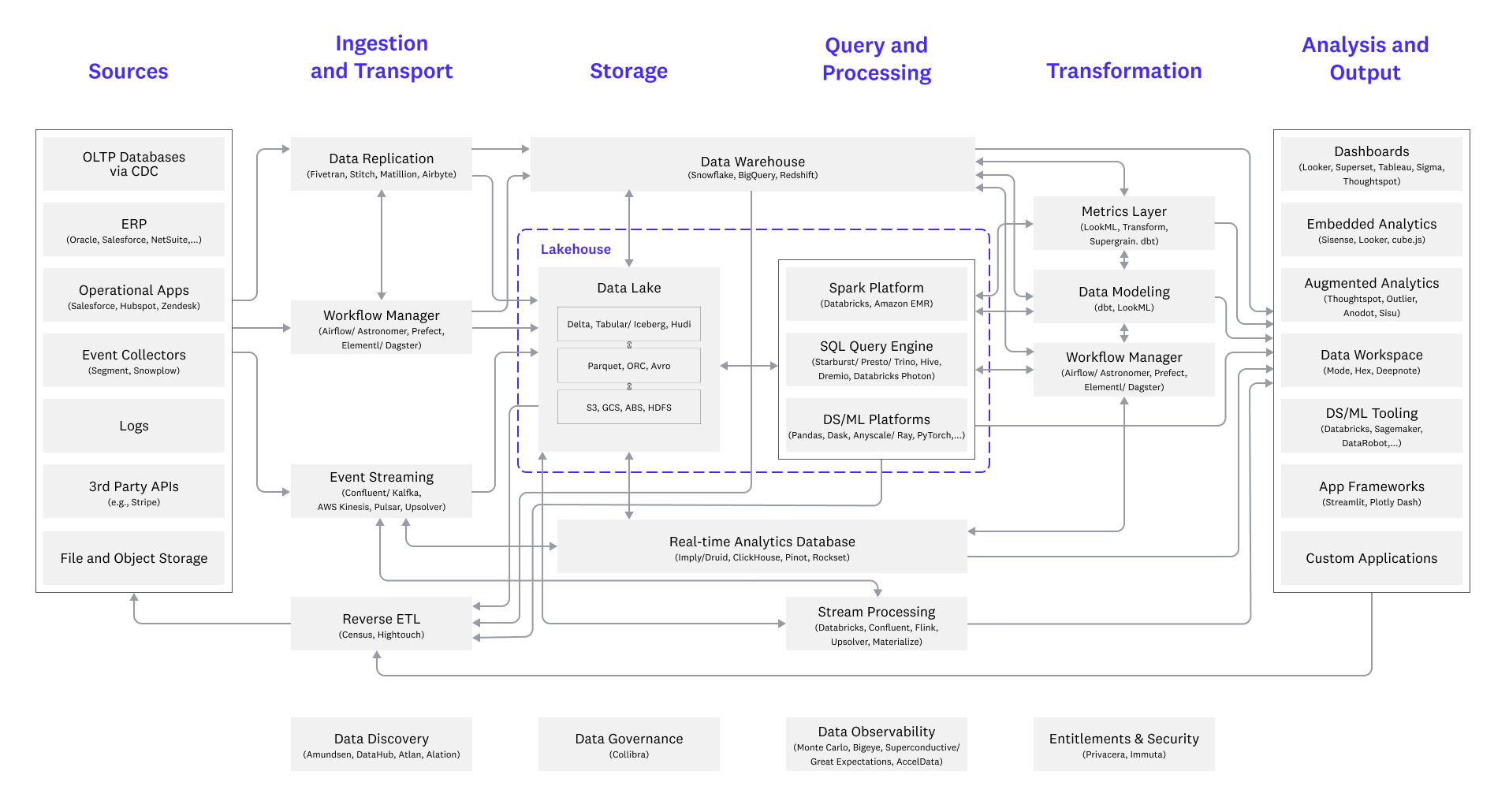
From components to a whole platform architecture
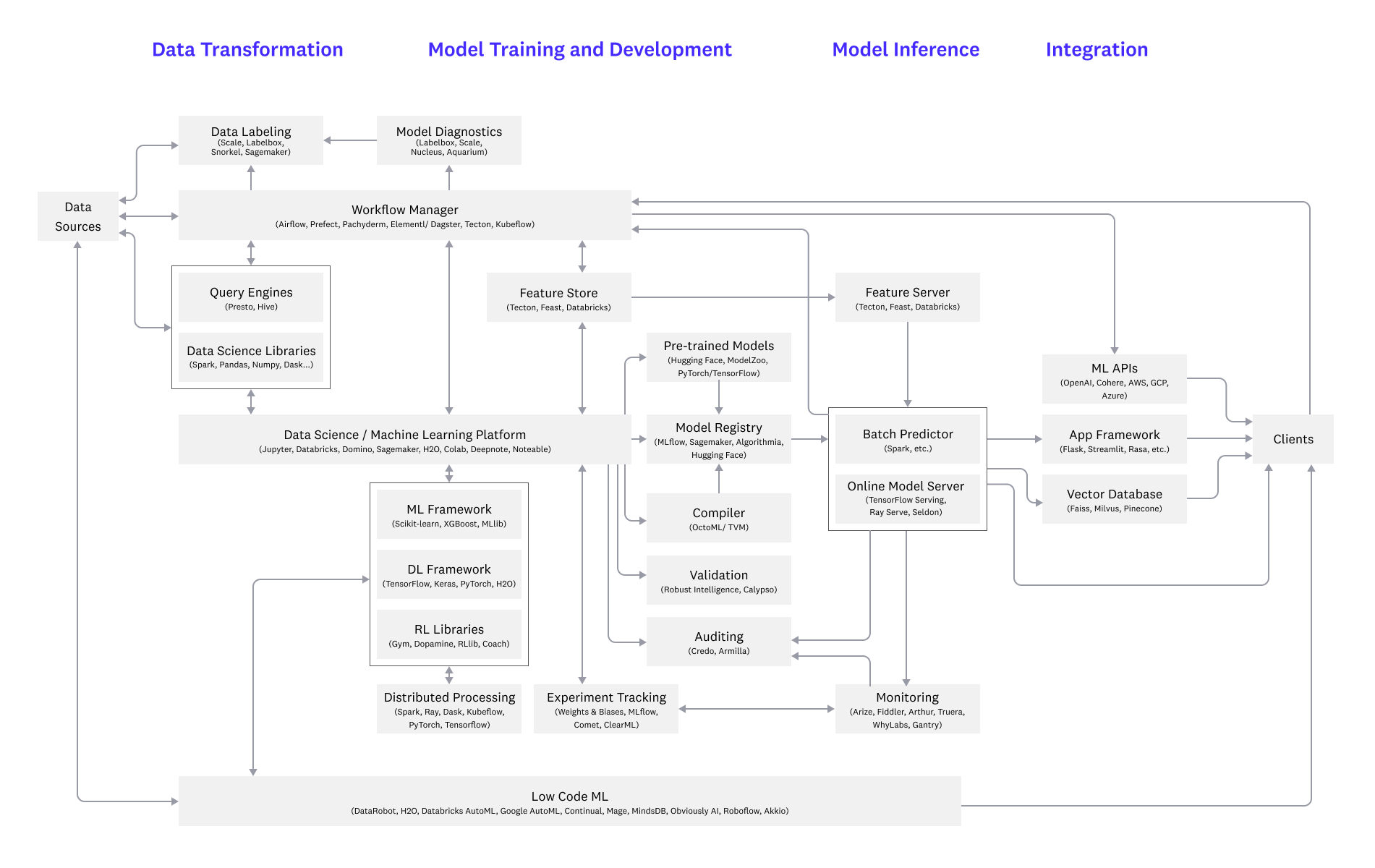
Big Data Is Dead
So has our dream come true?
We are getting very close …
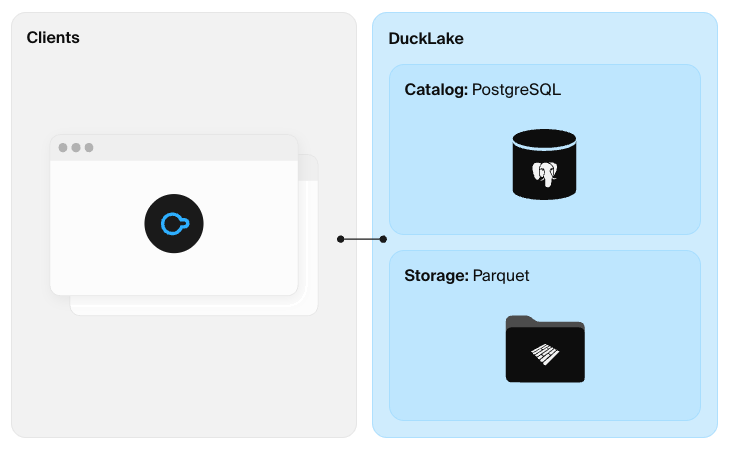
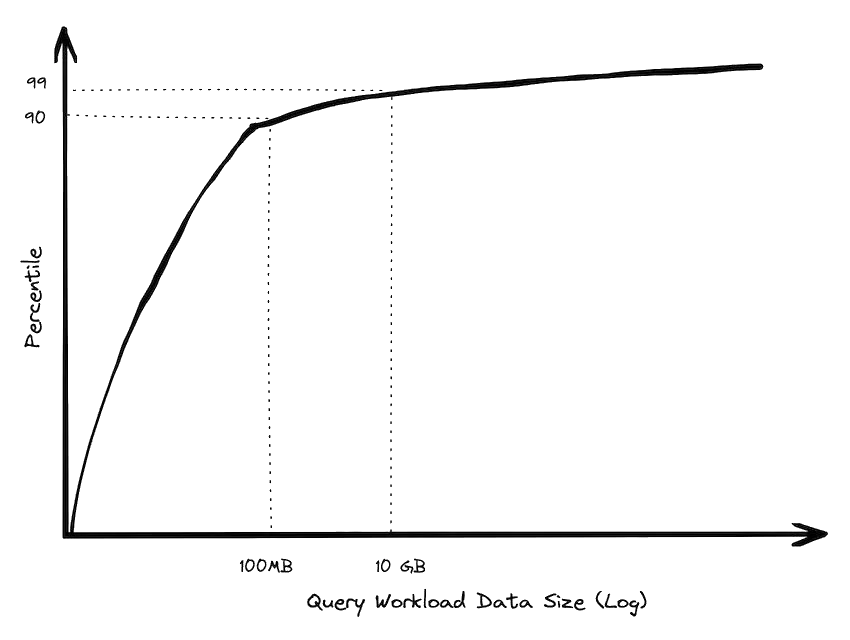
Diagonal scaling of a DuckLake lakehouse
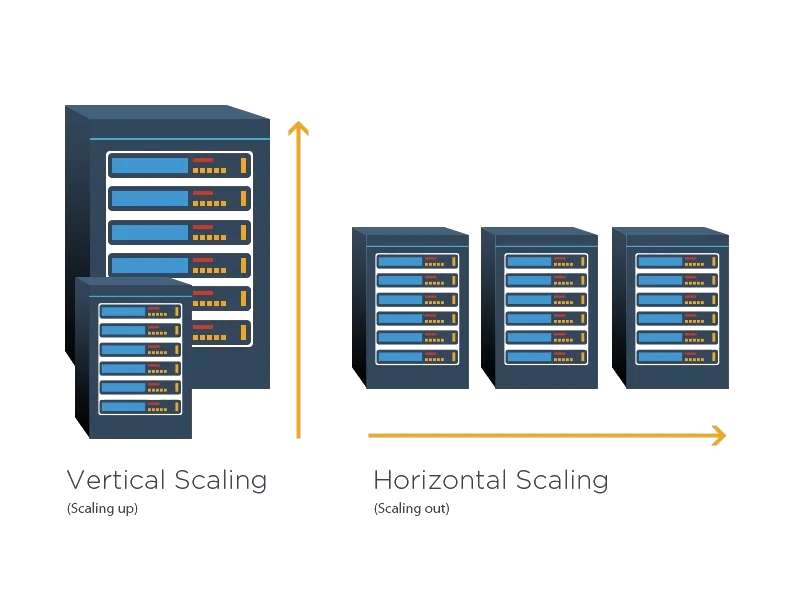
- Vertical scaling of single node query engines that can process up to 100 TB, covering 99% of use cases
- Horizontal scaling of blob storage in (sovereign!) data centres
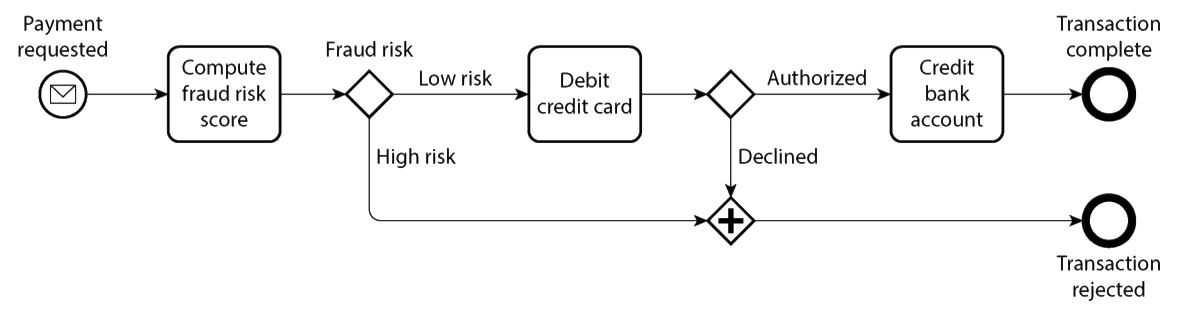
ETL, ELT, DAGs, pipelines, dataflows: it’s all the same
Business process models are also directed acyclic graphs
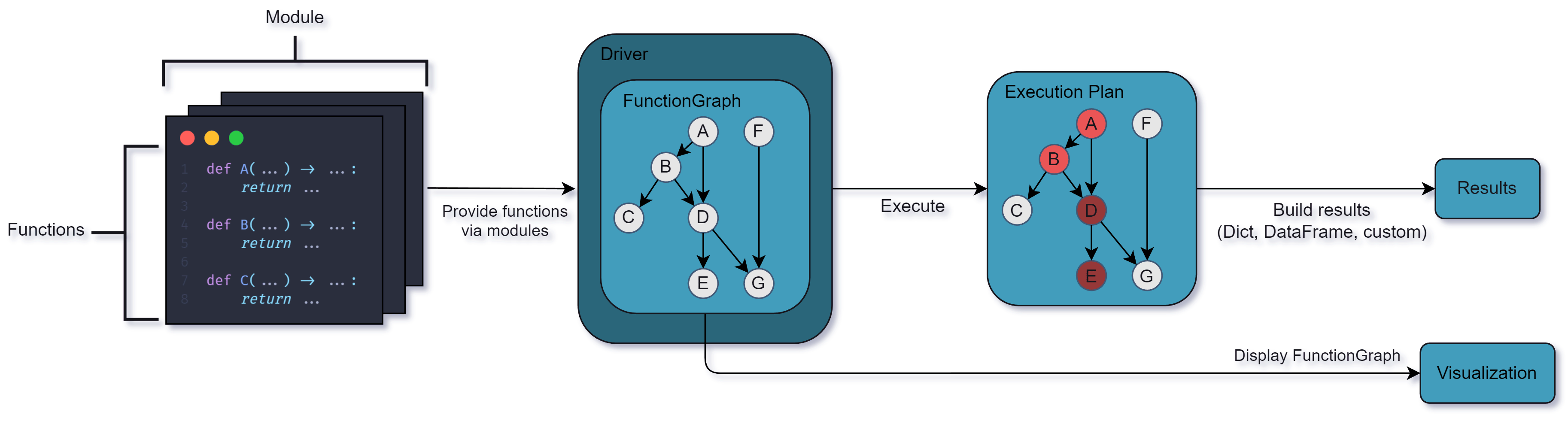
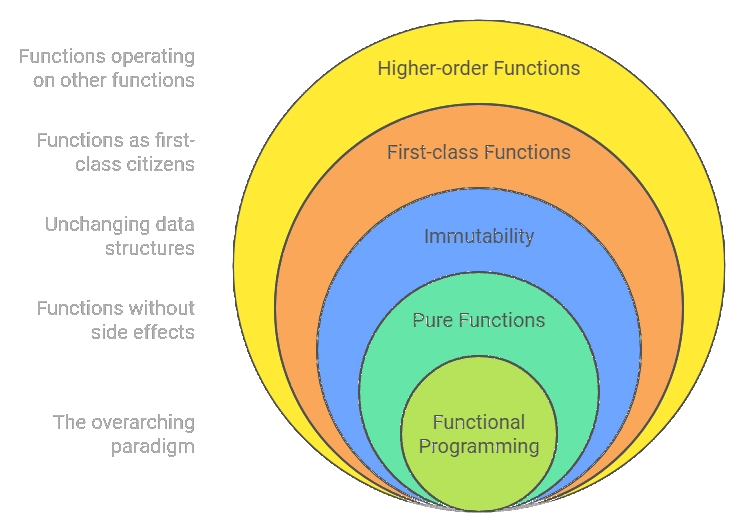
Batch data processing has a strong functional flavour
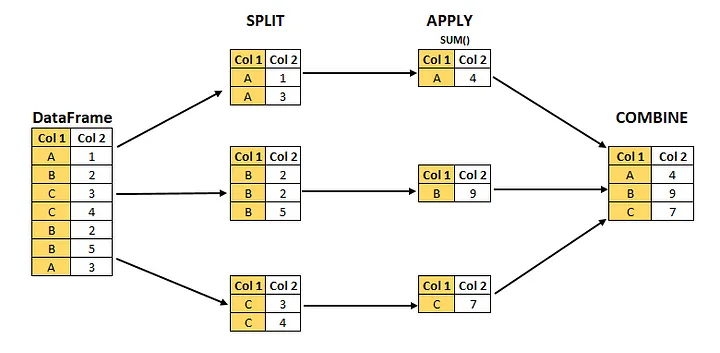
The split-apply-combine strategy for data analysis
Functional programming
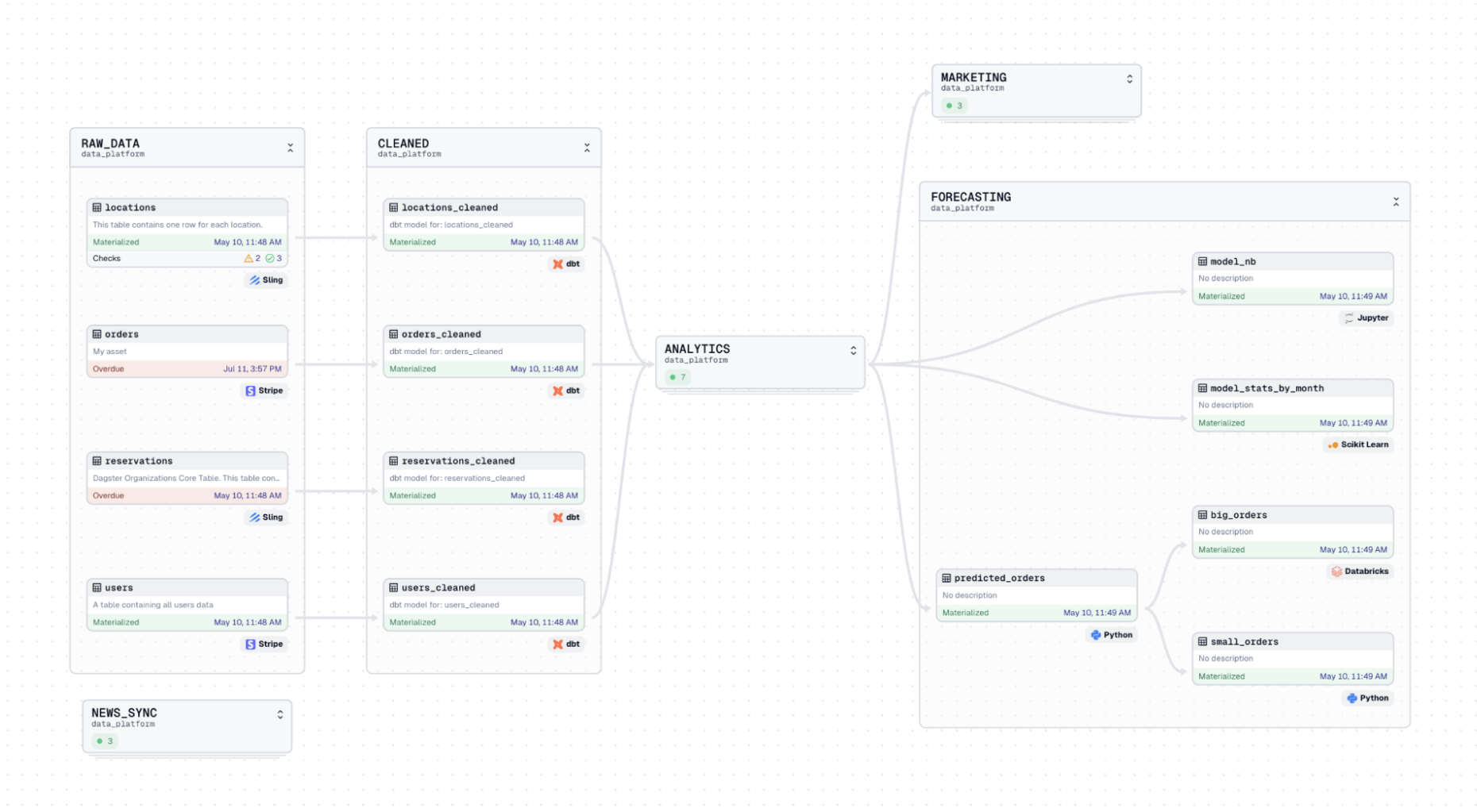
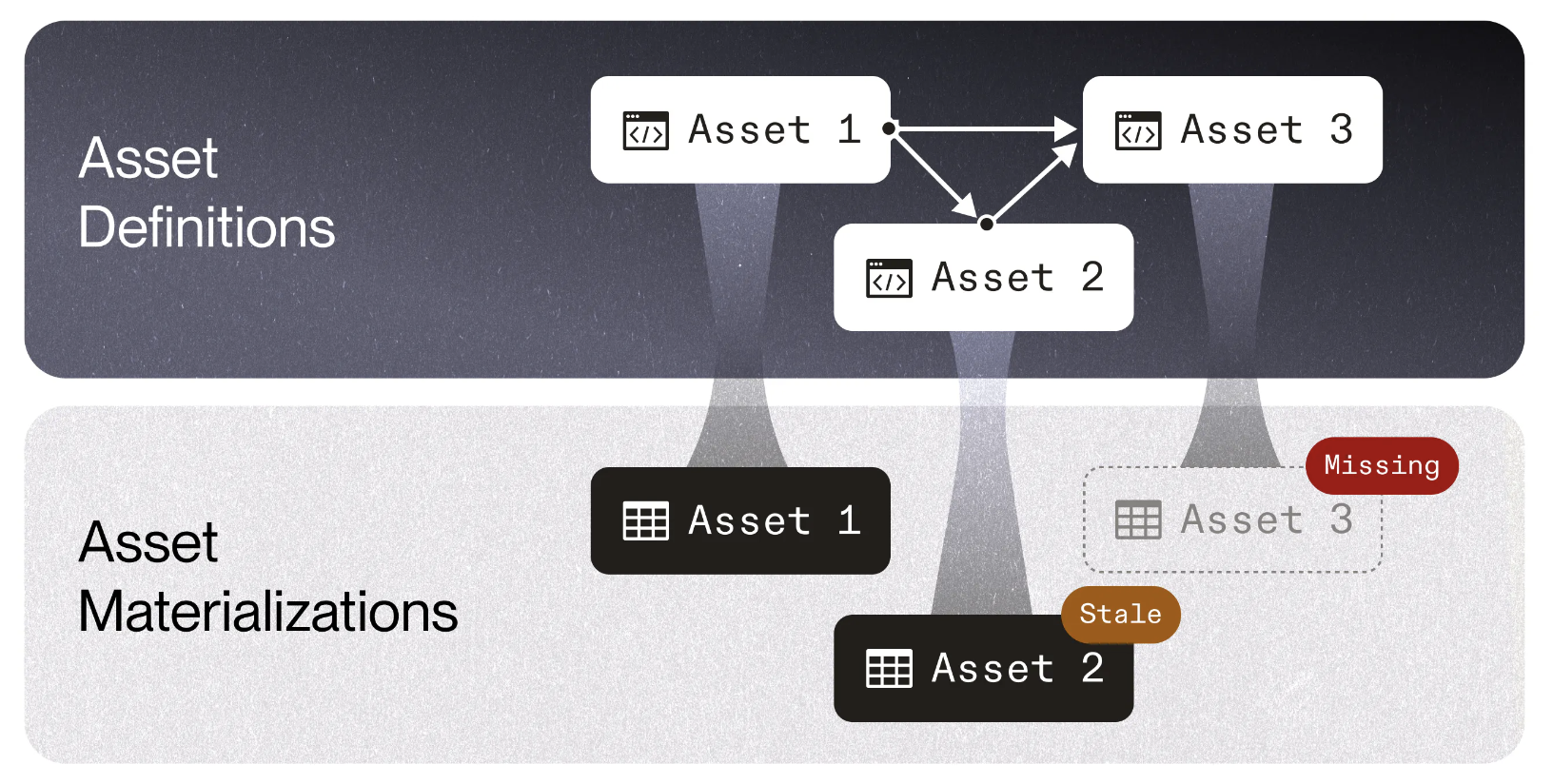
Introducting Software-Defined Assets
Stages of machine learning CI/CD automation pipeline
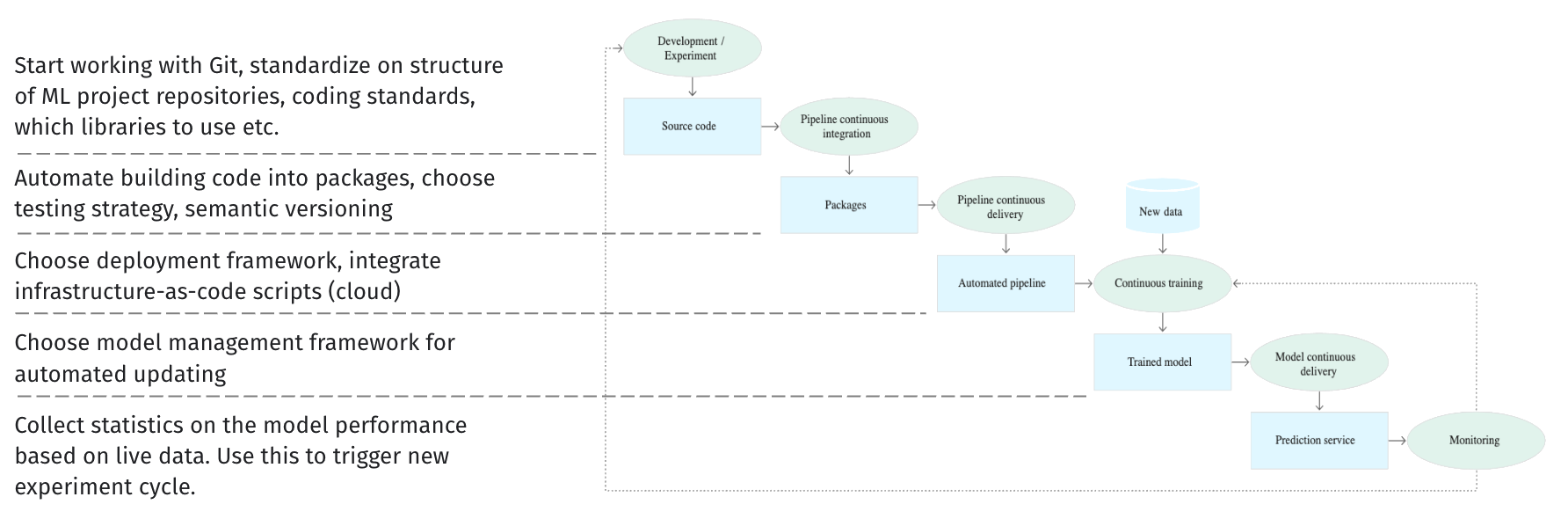
MLOps level 0

MLOps level 1

MLOps level 2

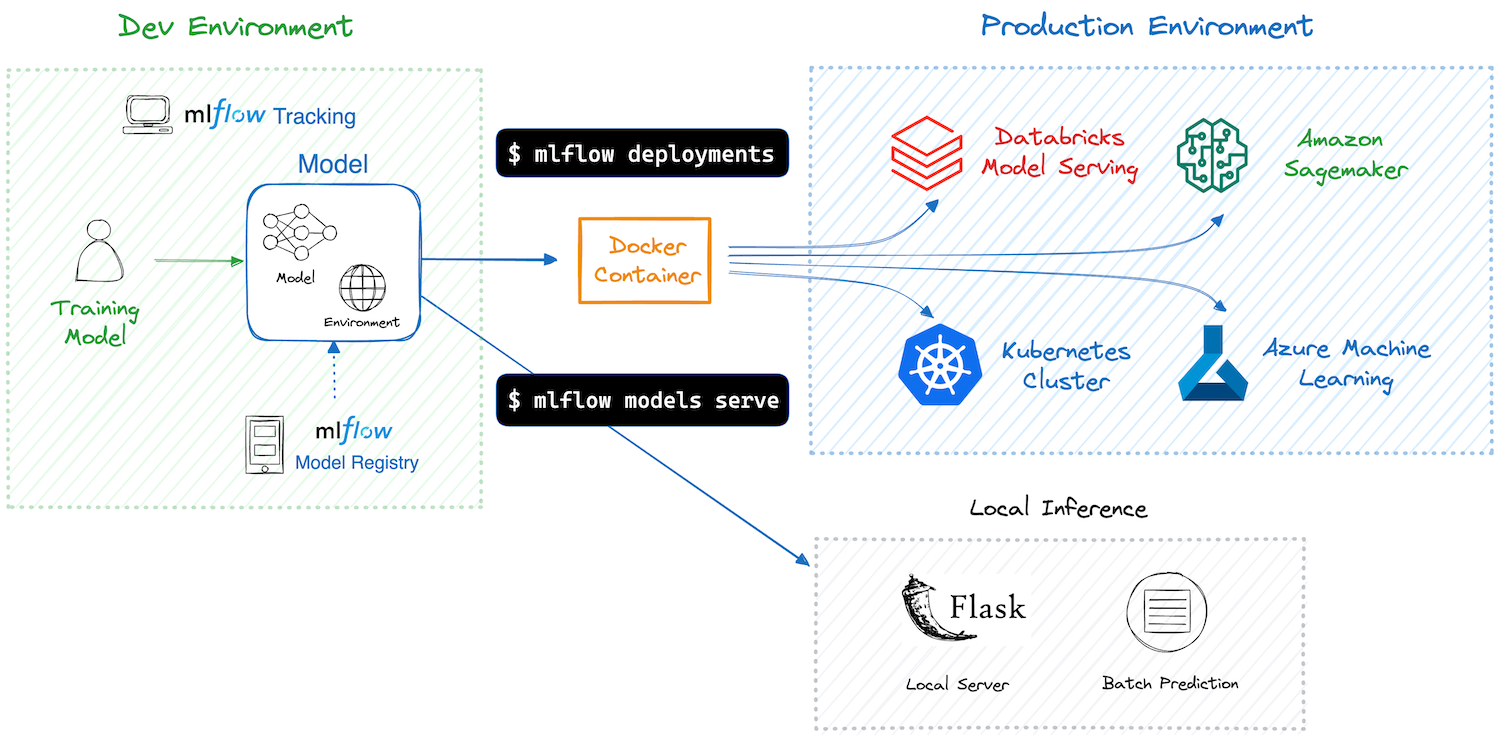
The most complete open source MLOps library

MLflow Tracking & Experiments
MLflow Model Registry
MLflow Model Deployment