Attribution & copyright notice
This lecture is based on many open access materials for which references are given on each slide. We highlight the following resources, which provide the backbone of the main narrative:
- L. Fioridi (2009), Philosophical Conceptions of Information
- Voltron Data, The Composable Codex
- Documentation of the following Python libraries:
DuckDB, polars, Ibis, dagster, hamilton, Shiny for Python, marimo - Better Images of AI, for non-stereotypical and thought provoking images
Source code: https://github.com/anthology-of-data-science/lecture-engineering-data-ai-platforms
This work is licensed under CC BY-SA 4.0![]()
![]()
![]()
The scope of real-world data science

The scope of real-world data science
Etymology
- datum: something given (fr. donné)
- informare: formation of the mind
- modulus: unit of measurement
- gnosis: knowledge
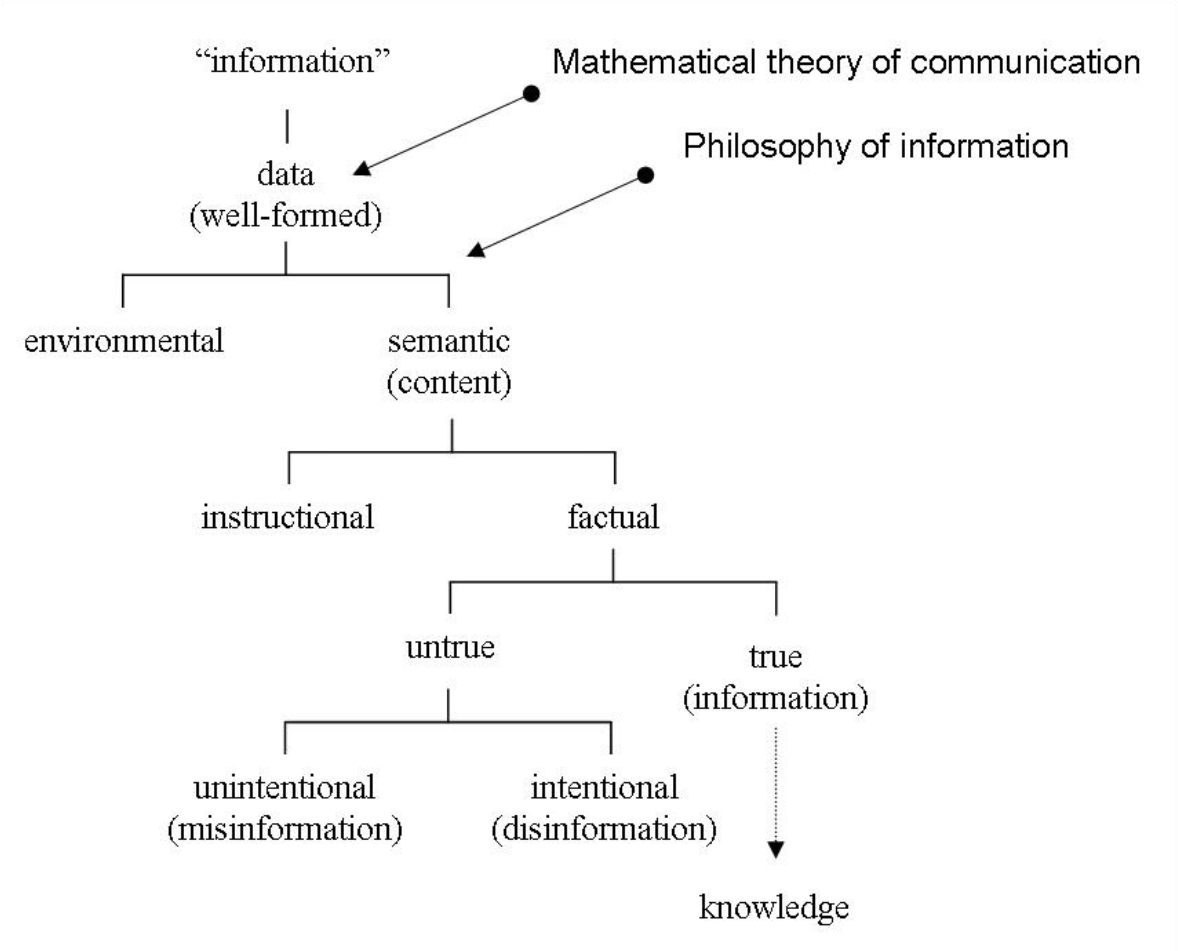
What are data?

- Data begins with counting
- From relational databases to document databases and knowledge databases
- From data to information to knowledge
But what is “learning” and what are “models”?

- Models as tools to obtain factual knowledge
- Different types of models: machine learning model, generative AI model, causal model, deductive model
- How does data science and “AI” change how we work with models?
The Ladder of Causality

Remember:
- Machine learning models are not the only models
- Machine learning models are only based on correlations
- Machine learning can not reason (although LLMs look like they can)
- Read more on analytical problem with different types of models
Using data and models in real-world applications

- Platforms for working with data and models
- Governance of data & models in organizations
- Ethical, legal and societal impact of using data & models
- Human-computer interactions
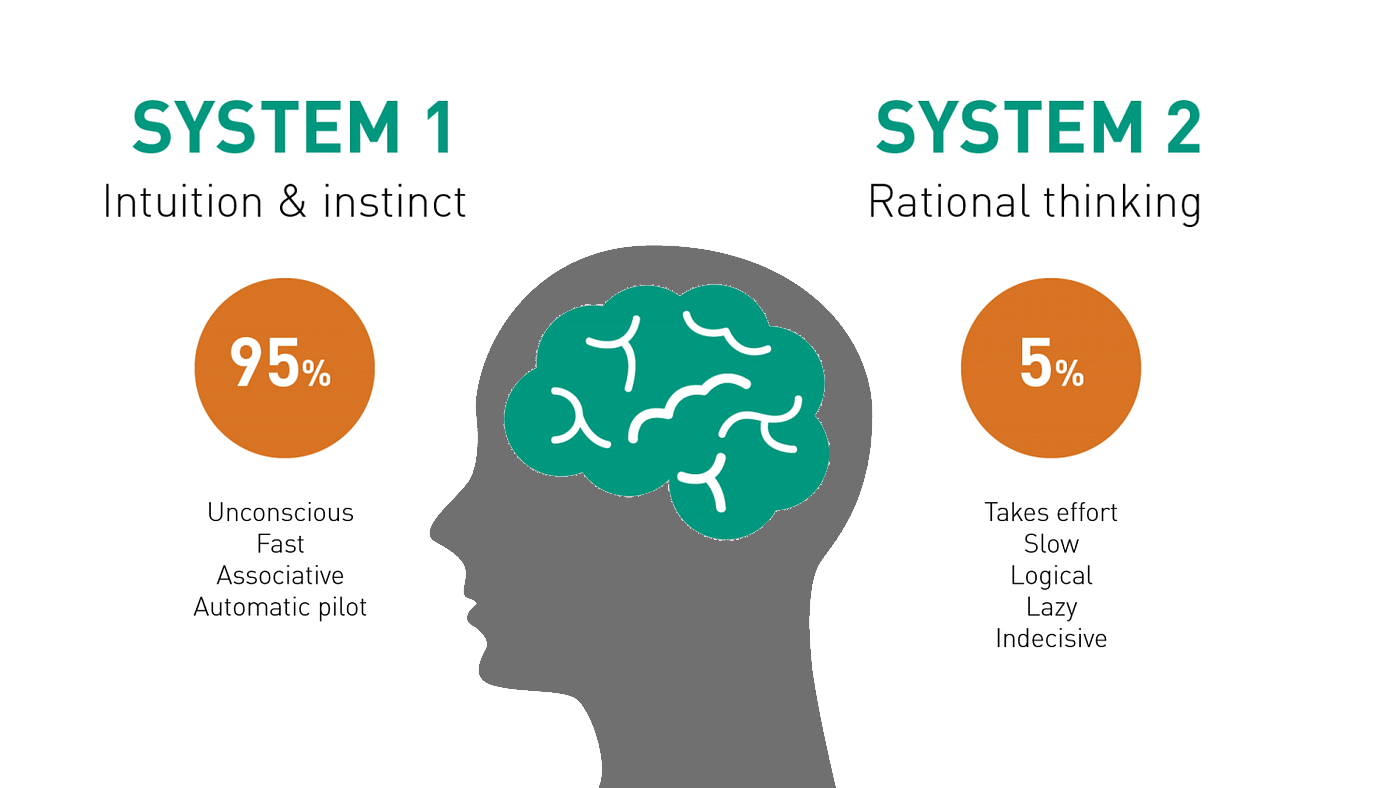
Thinking, Fast and Slow
Data starts with counting

Bone of Lembobo
- Oldest tally stick, 40,000 years old
- 29 marks: lunar cycle, menstrual cycle?
- … but piece is missing, perhaps it continued counting
Bone of Ishango (picture left)
- 20,000 years old
- 168 parallel notches in all, engraved on three sides, arranged in group
- Meaning remains unclear
Data starts with counting

Mesopotamia, around 3300 BC
- One of the world’s earliest civilizations: animal husbandry, cultivation of crops
- Symbolic accounting system in cuneiform
- Use of sexagesimal numbers with number 60 as root: twelve finger joints of one hand and five fingers of the other
Tidy data

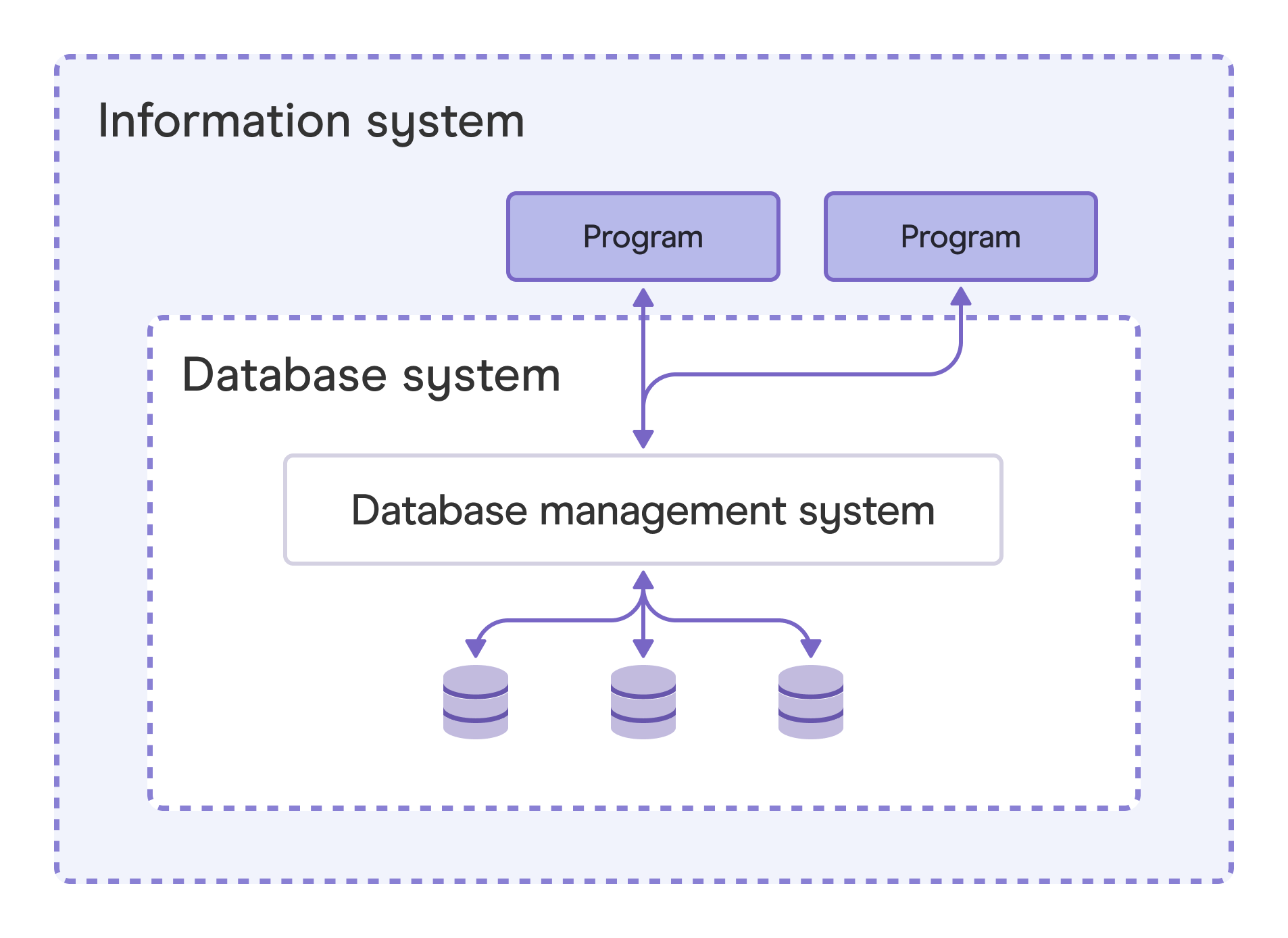
It all started with the relational database management system (RDBMS)

Databases are often at the heart of an information system
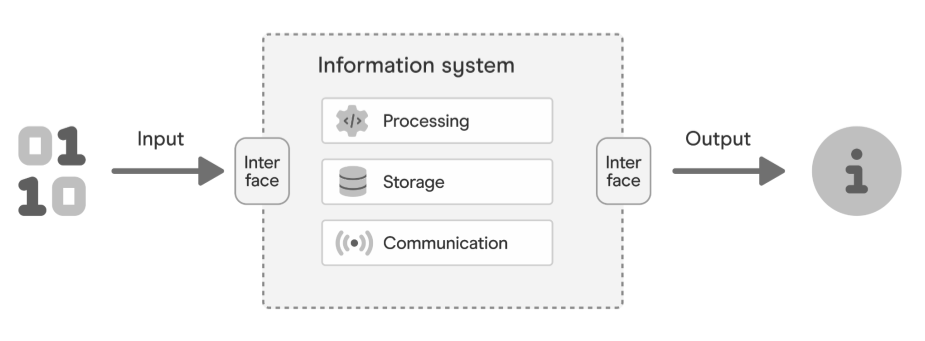
Databases are often at the heart of an information system
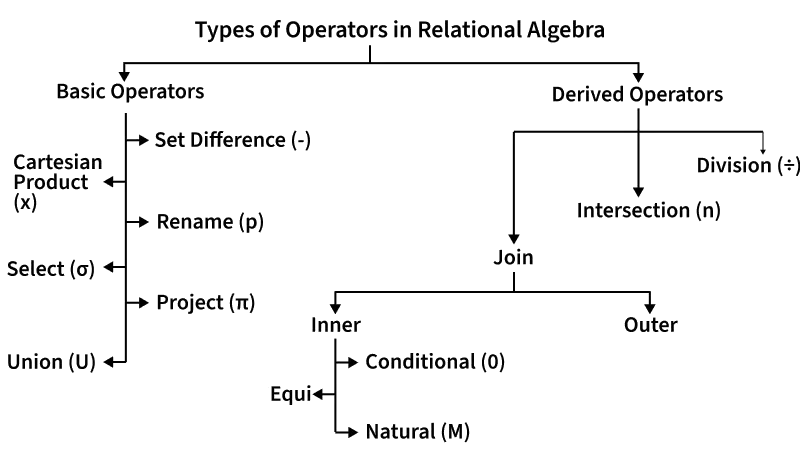
Relational algebra as the mathematical foundation
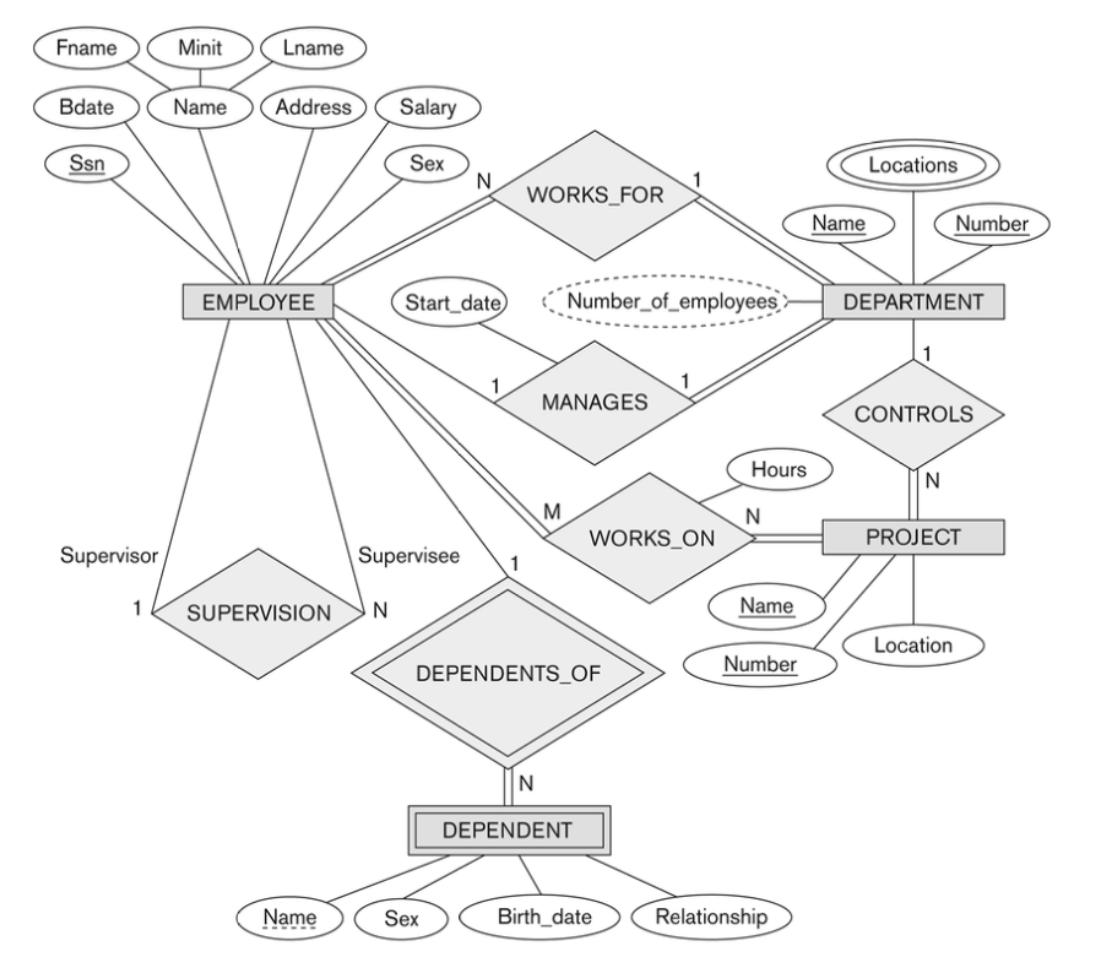
Chen notation

Solution
Four layers of data modeling

- Semantic:
fact-based modeling, ontology modeling - Conceptual:
Entity-relationship modeling, UML modeling - Logical:
dimensional modeling, data vault modeling - Physical: DuckDB, Polars, SQL Server etc.
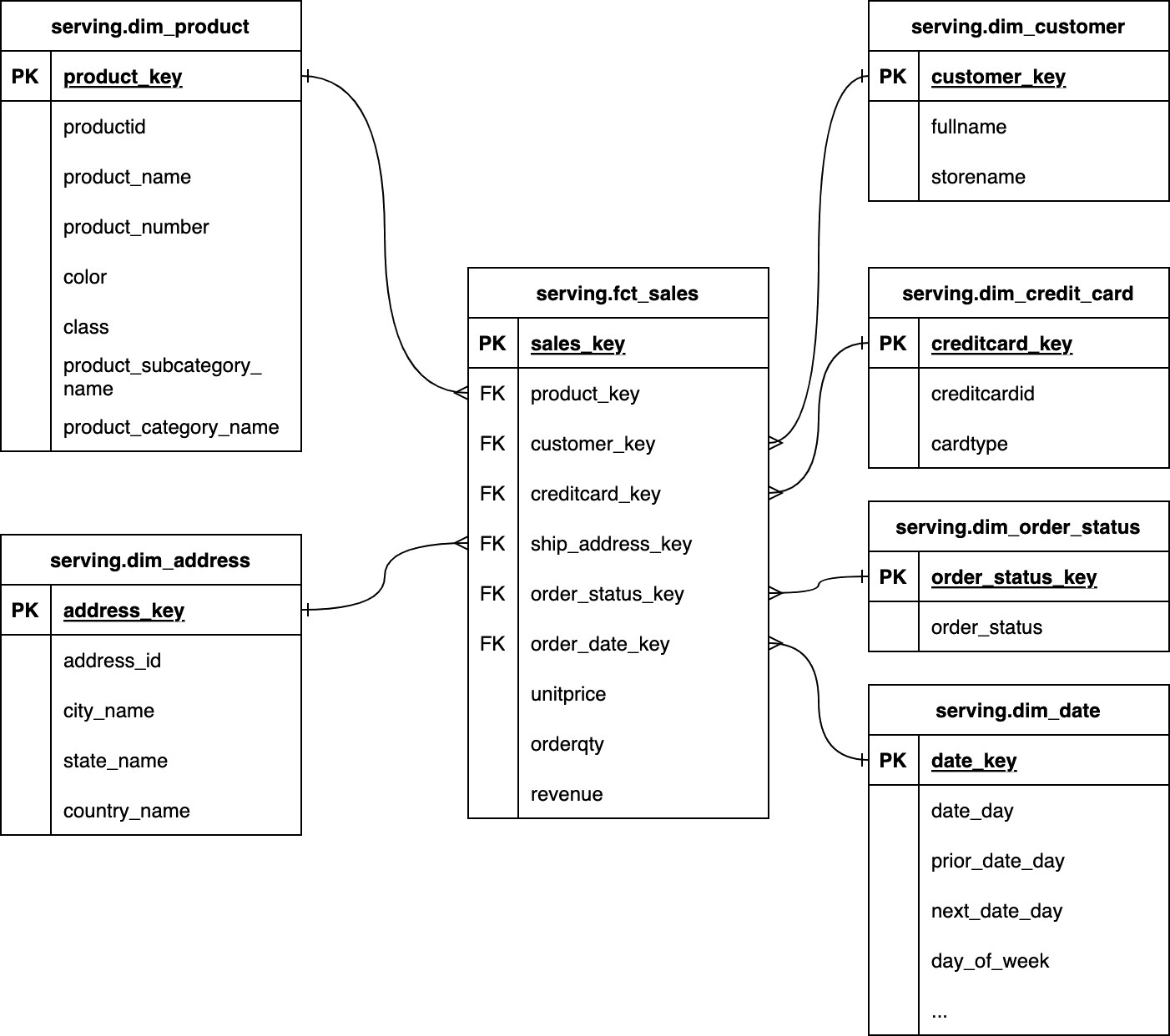
Relational models in datawarehouses: the dimensional model (aka star schema)
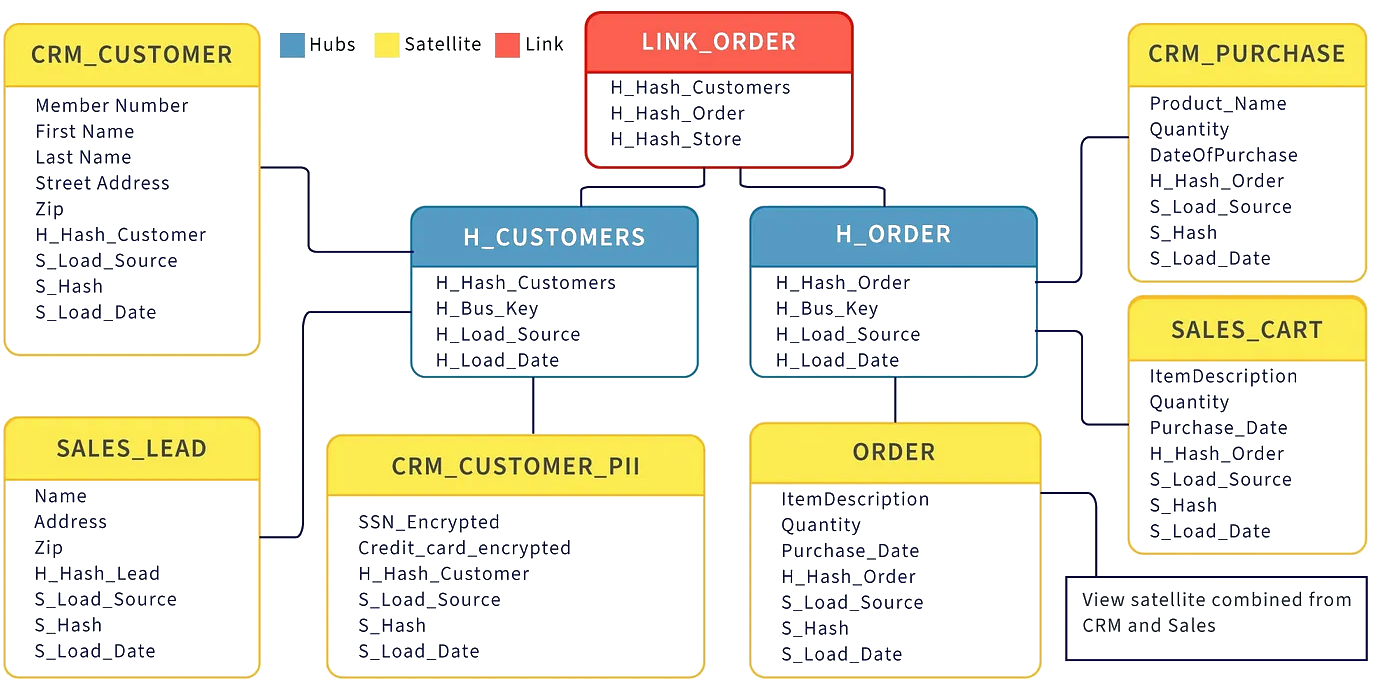
Relational models in datawarehouses: the data vault
The relational model vs. the document model
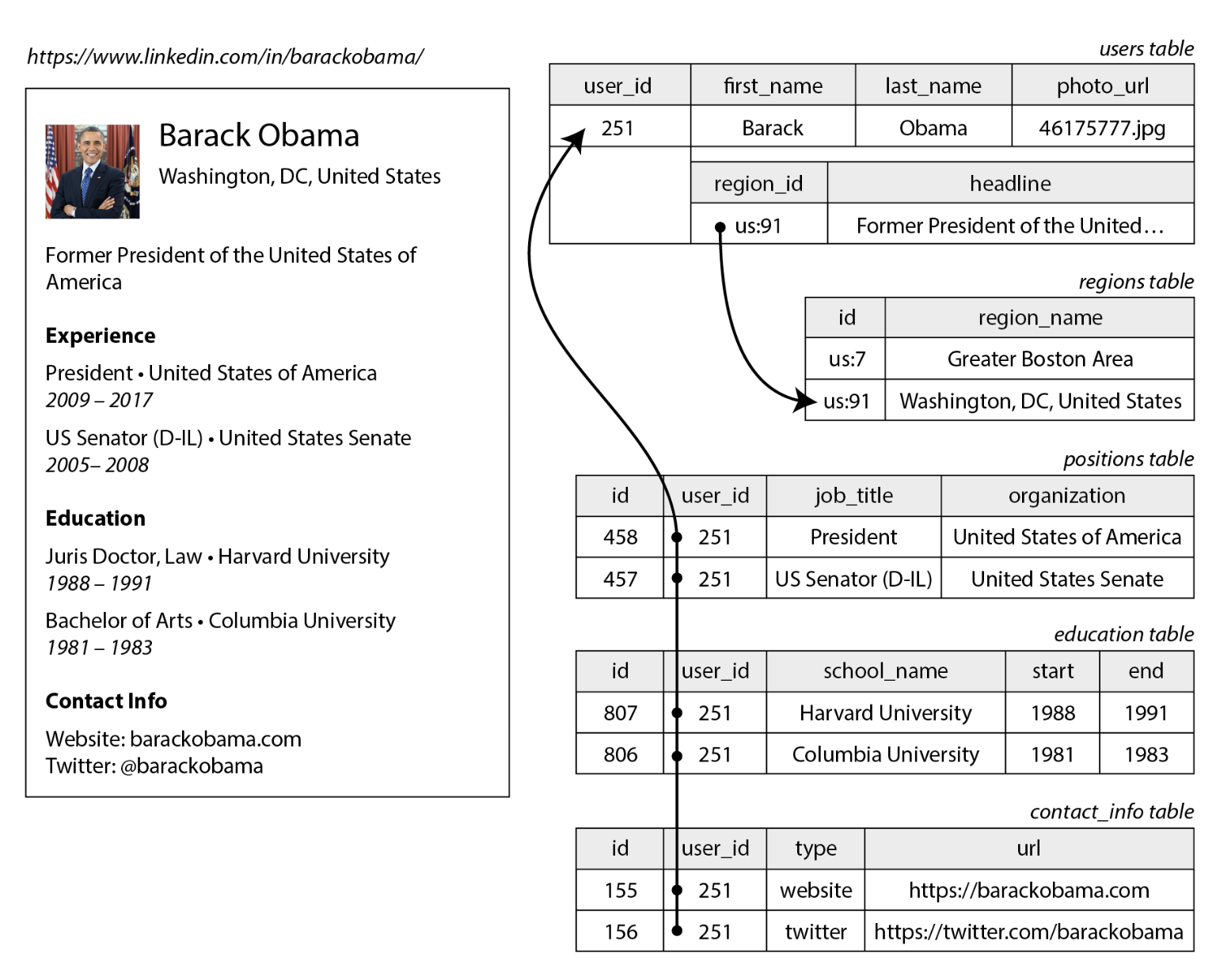
The relational model vs. the document model

{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "https://barackobama.com",
"twitter": "https://twitter.com/barackobama"
}
}But semantics often get lost in data models
Example: different conceptualizations of sex and gender
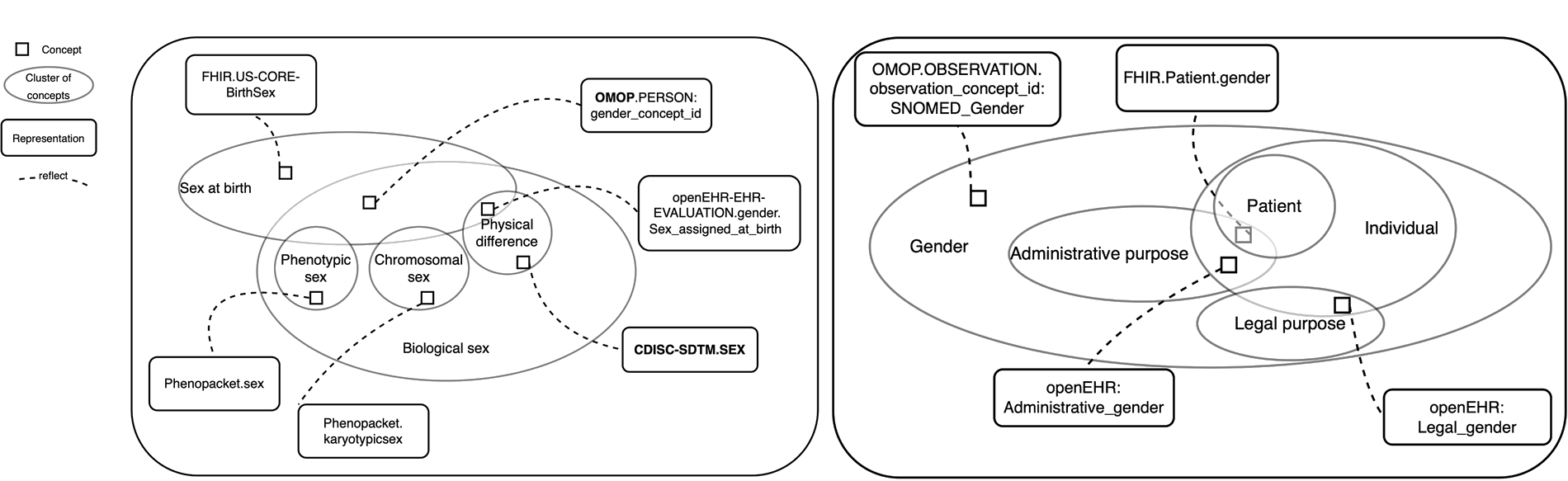
From data to information and knowledge
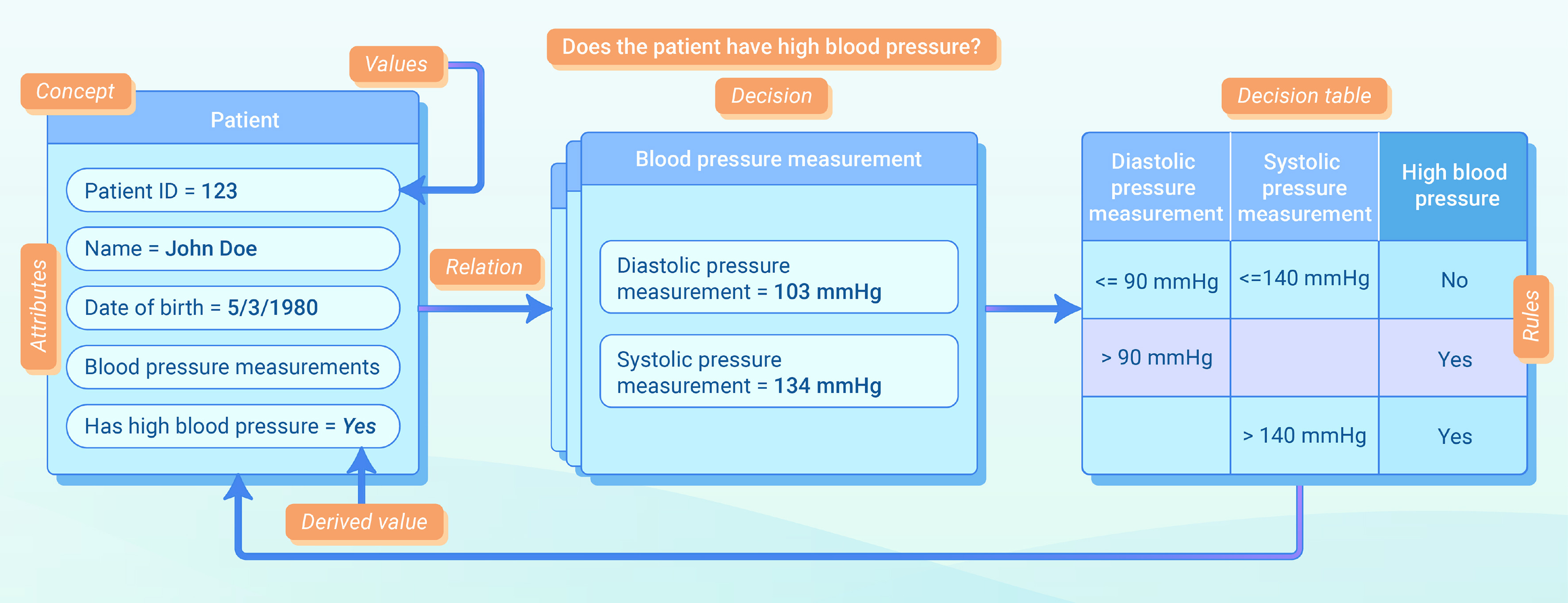
The semantics of blood pressure
The return of the knowledge graph
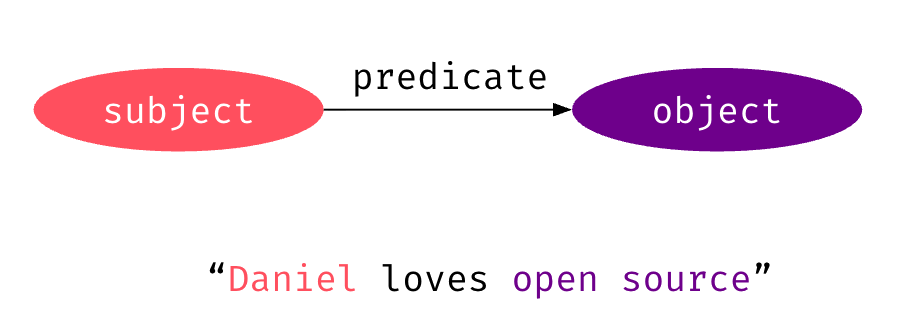
Semantic triples
- A semantic triple, or RDF triple or simply triple, is the atomic data entity in the Resource Description Framework (RDF) data model
- A triple is a sequence of three entities that codifies a statement about semantic data in the form of subject–predicate–object expressions
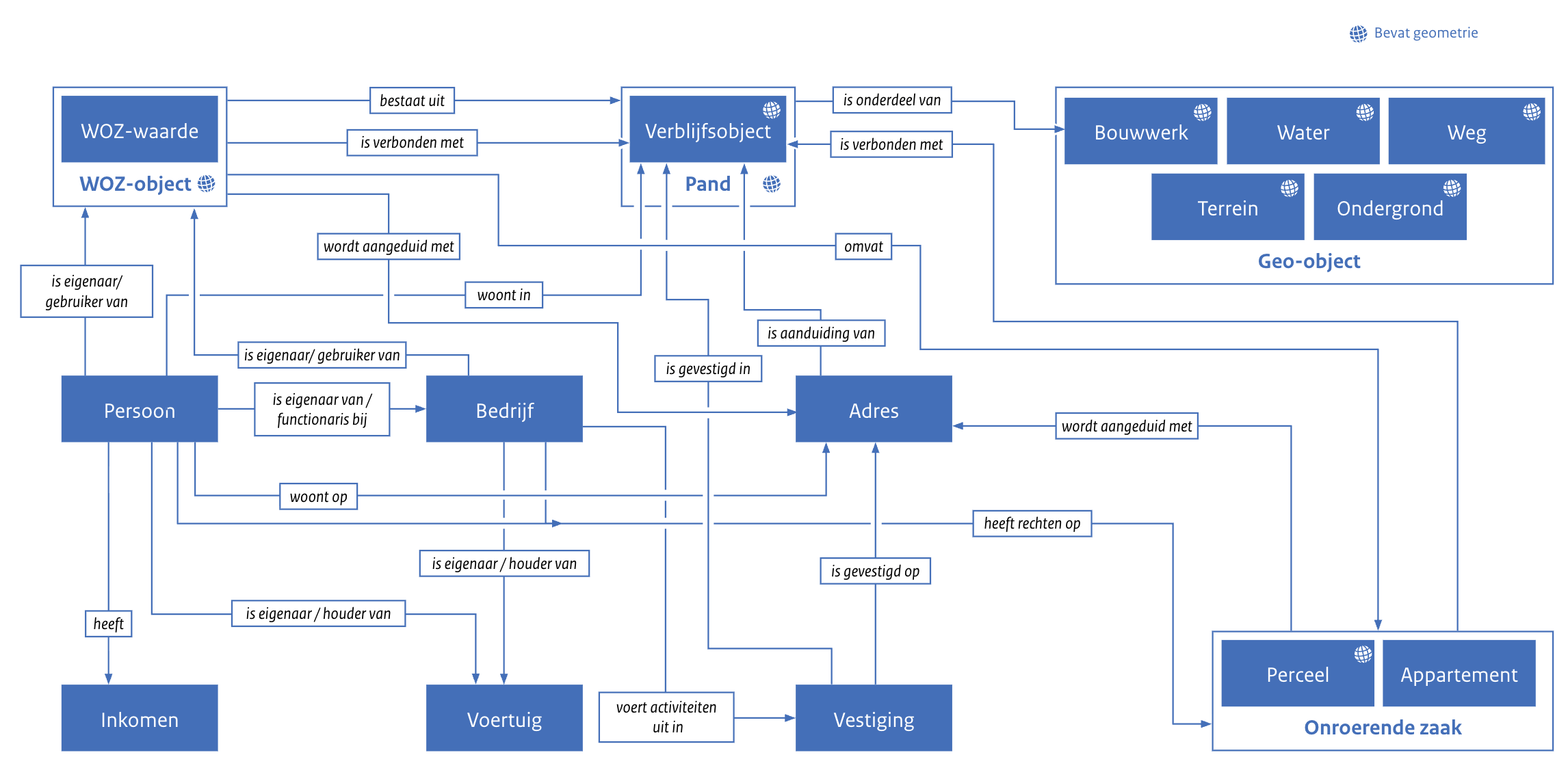
Stelselgegevens basisregistraties
The Ontology Pipeline
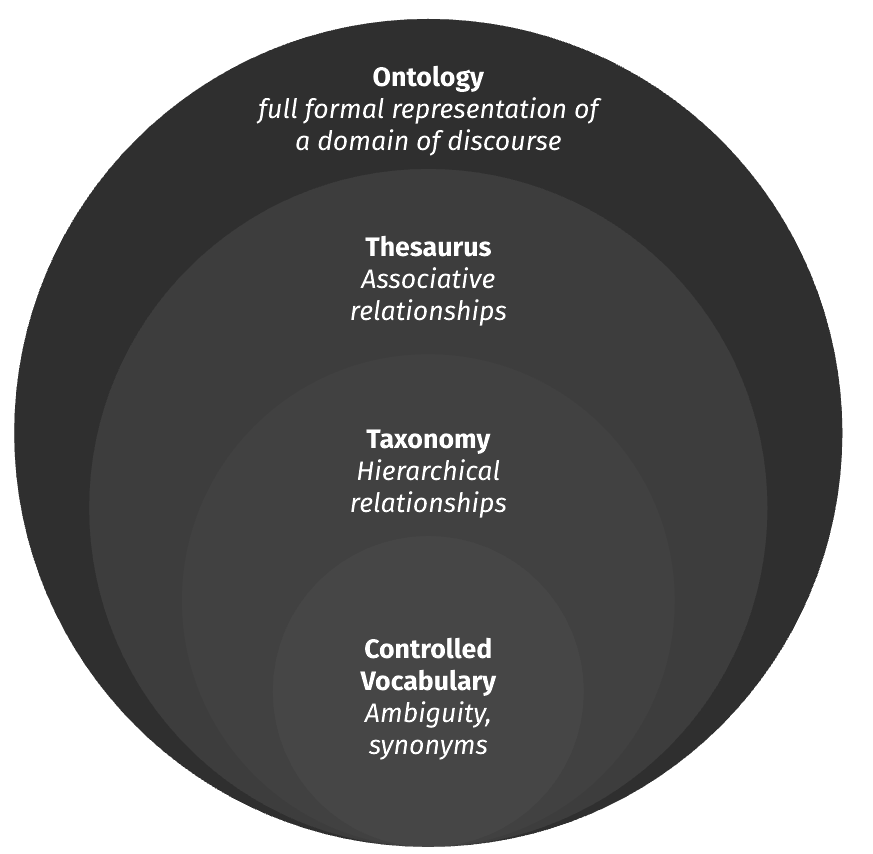
Ontologies enhance vocabularies by describing and contextualizing relationships between concepts and with the introduction of logical reasoning. By assigning classes, properties, relations and attributes, ontologies establish rule bases that define how concepts behave in the wild, ensuring a level of coherence within complex information systems. Machines love ontologies because of their high-fidelity disambiguation and description, which bring clarity to machine understanding for tasks such as information retrieval, entity management, concept discovery, and RAG implementations for AI systems.
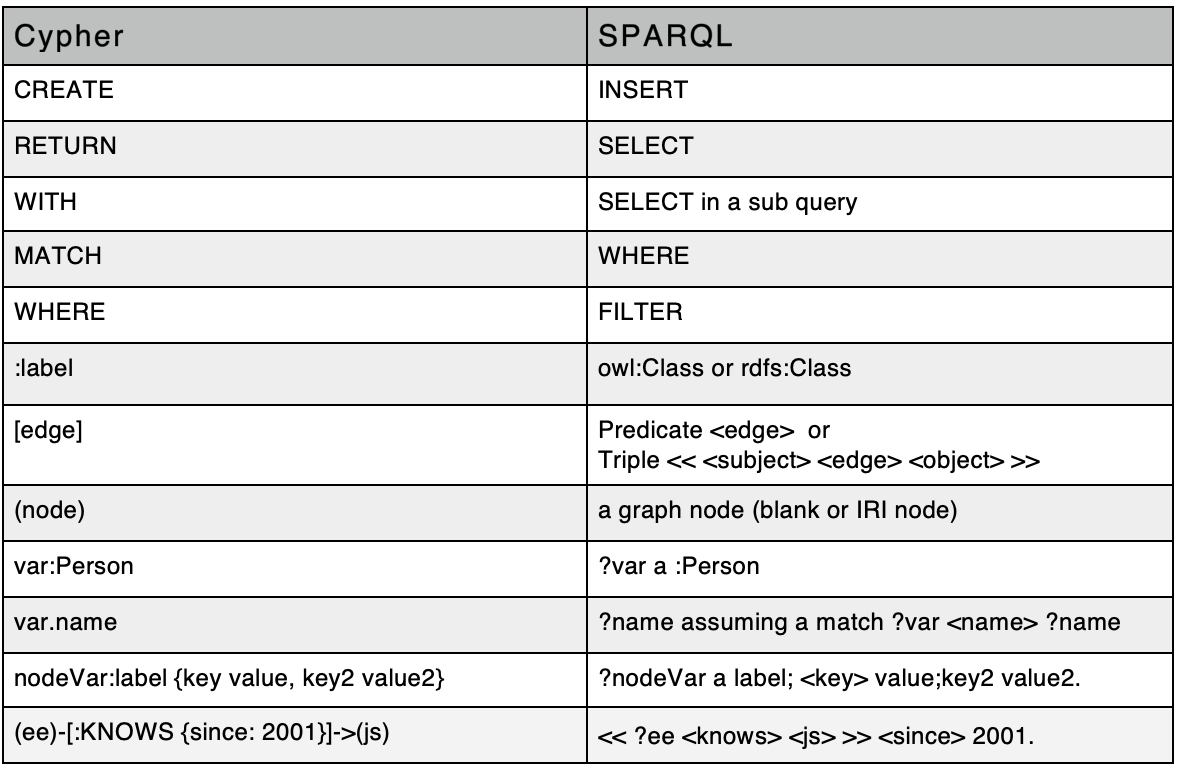
SPARQL vs. Cypher/GQL comparison
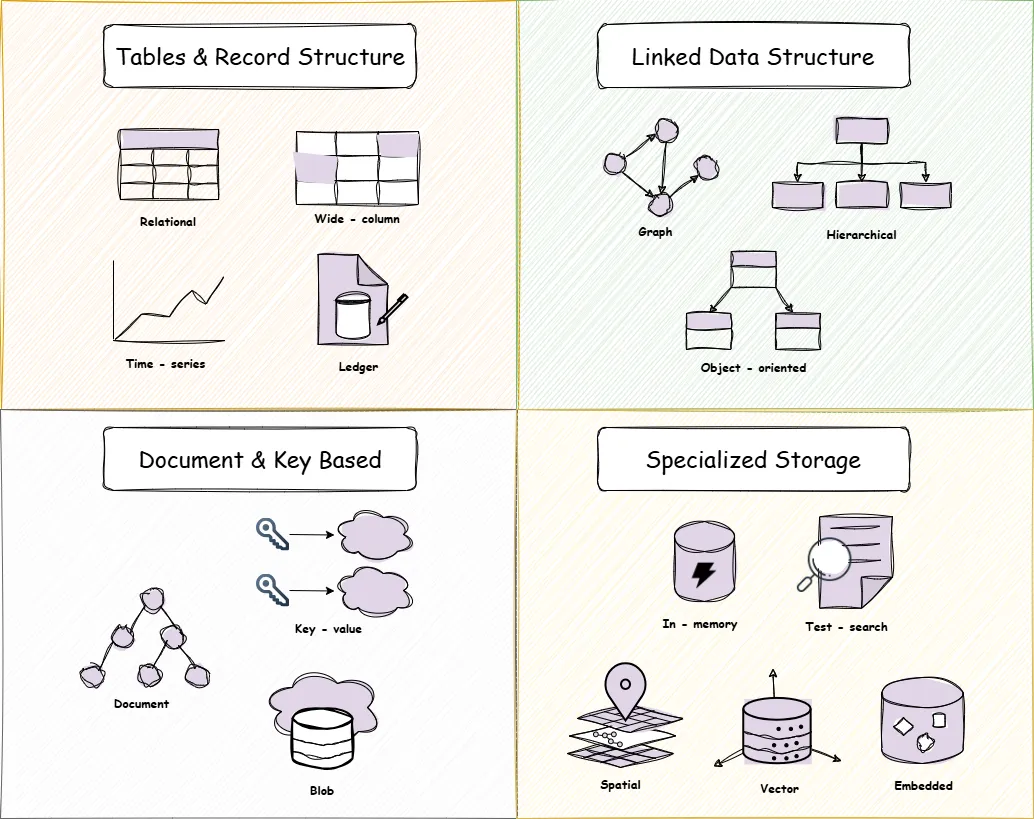
Choose your data structure and engine wisely
The elephant is your friend
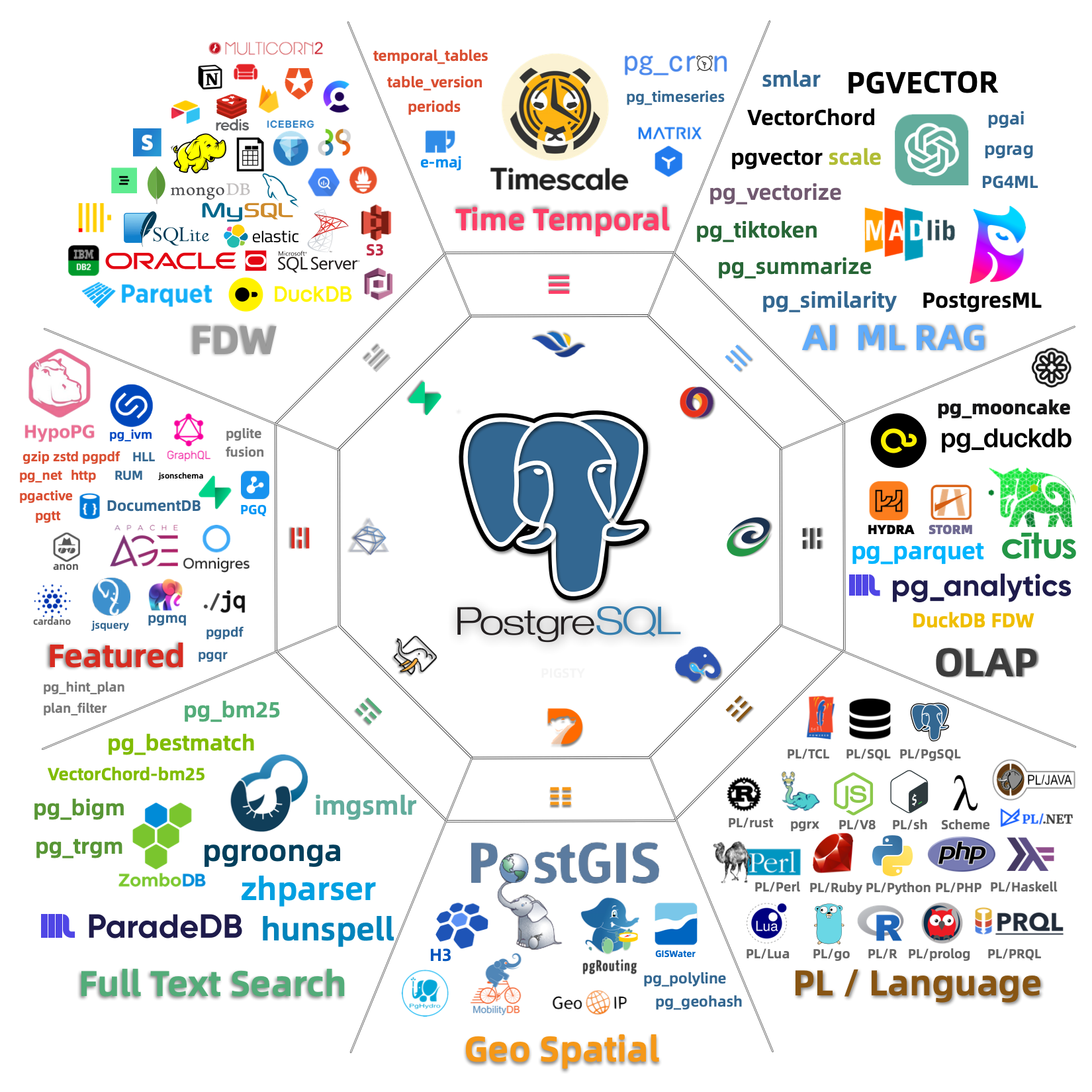
- One physical engine: PostgreSQL is the most widely used open source relational database management system
- Supports different data structures: not only relational but also document model (JSONB) and labeled property graph (Apache AGE)
- … plus many use-case specific extensions such as time-series database, spatial database etc.
How to manage
the data science lifecycle in real-world applications?

The best book on data engineering
- Chapter 1: Tradeoffs in Data Systems Architecture
Analytical versus Operational Systems - Cloud versus Self-Hosting - Distributed versus Single-Node Systems - Data Systems, Law, and Society - Chapter 2: Defining Nonfunctional Requirements
Case Study: Social Network Home Timelines- Describing Performance - Reliability and Fault Tolerance - Scalability - Maintainability - Chapter 3: Data Models and Query Languages
Relational Model versus Document Model - Graph-Like Data Models - Event Sourcing and CQRS - DataFrames, Matrices, and Arrays - Chapter 4: Storage and Retrieval
Storage and Indexing for OLTP - Data Storage for Analytics - Multidimensional and Full-Text Indexes - (…)
- Chapter 11: Batch Processing
Batch Processing in Distributed Systems - Batch Processing Models - Batch Use Cases

The common definition of data engineering
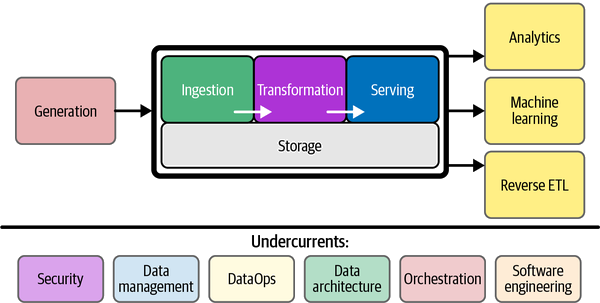
Our dream: a data system that just works
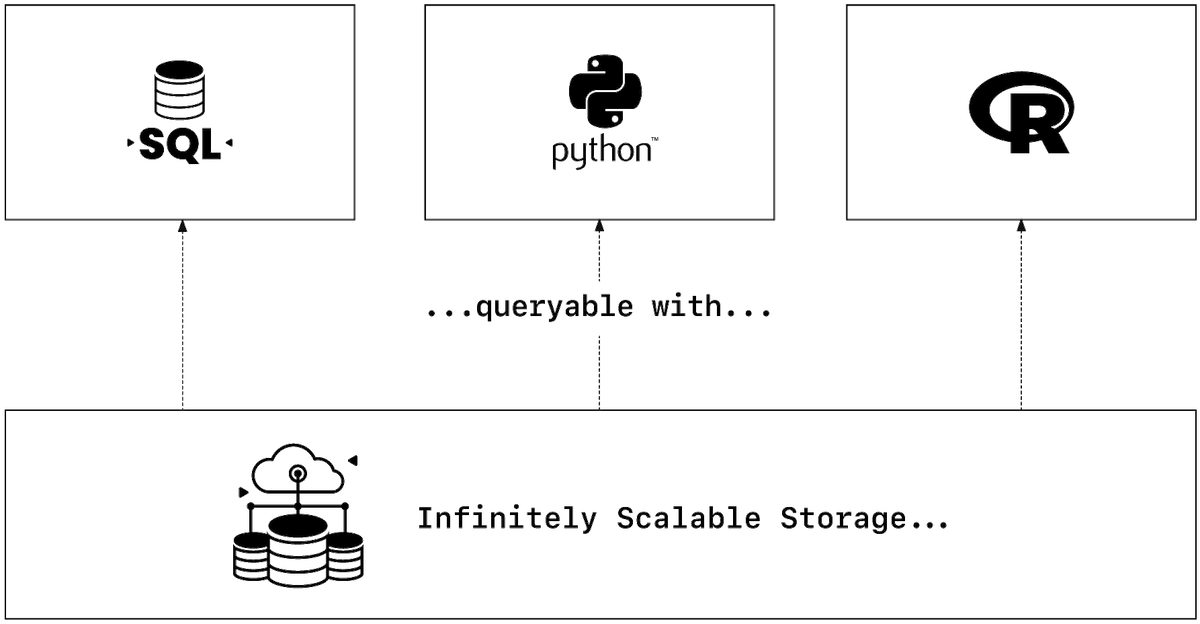
The problem

It all started with the relational database management system (RDBMS)
What makes a database?
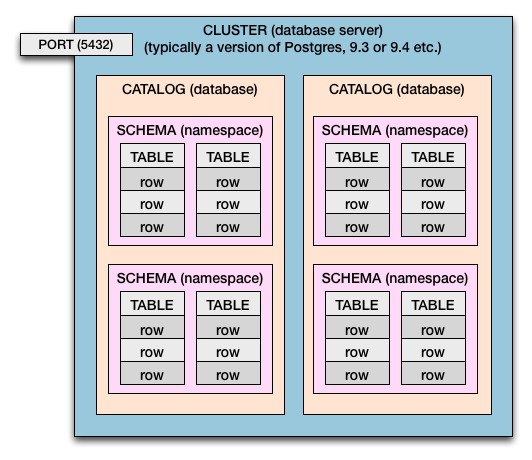
| System | Catalog | Database |
|---|---|---|
| postgresql, mysql, mssql, duckdb | database | schema |
| datafusion, trino | catalog | schema |
| druid | dataSourceType | dataSource |
| bigquery | project | database |
| flink | catalog | database |
| clickhouse | database | |
| clickhouse, impala, mysql, pyspark, snowflake | database |
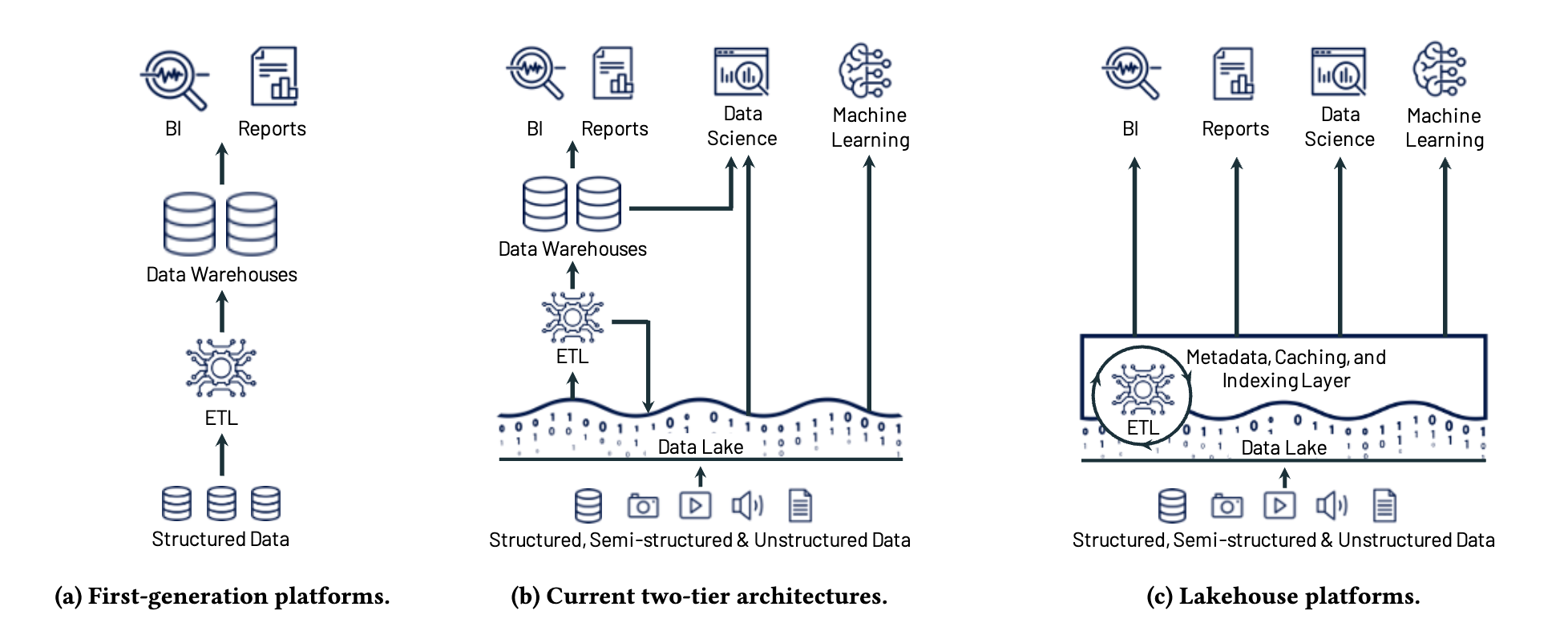
Evolution of analytical system architectures
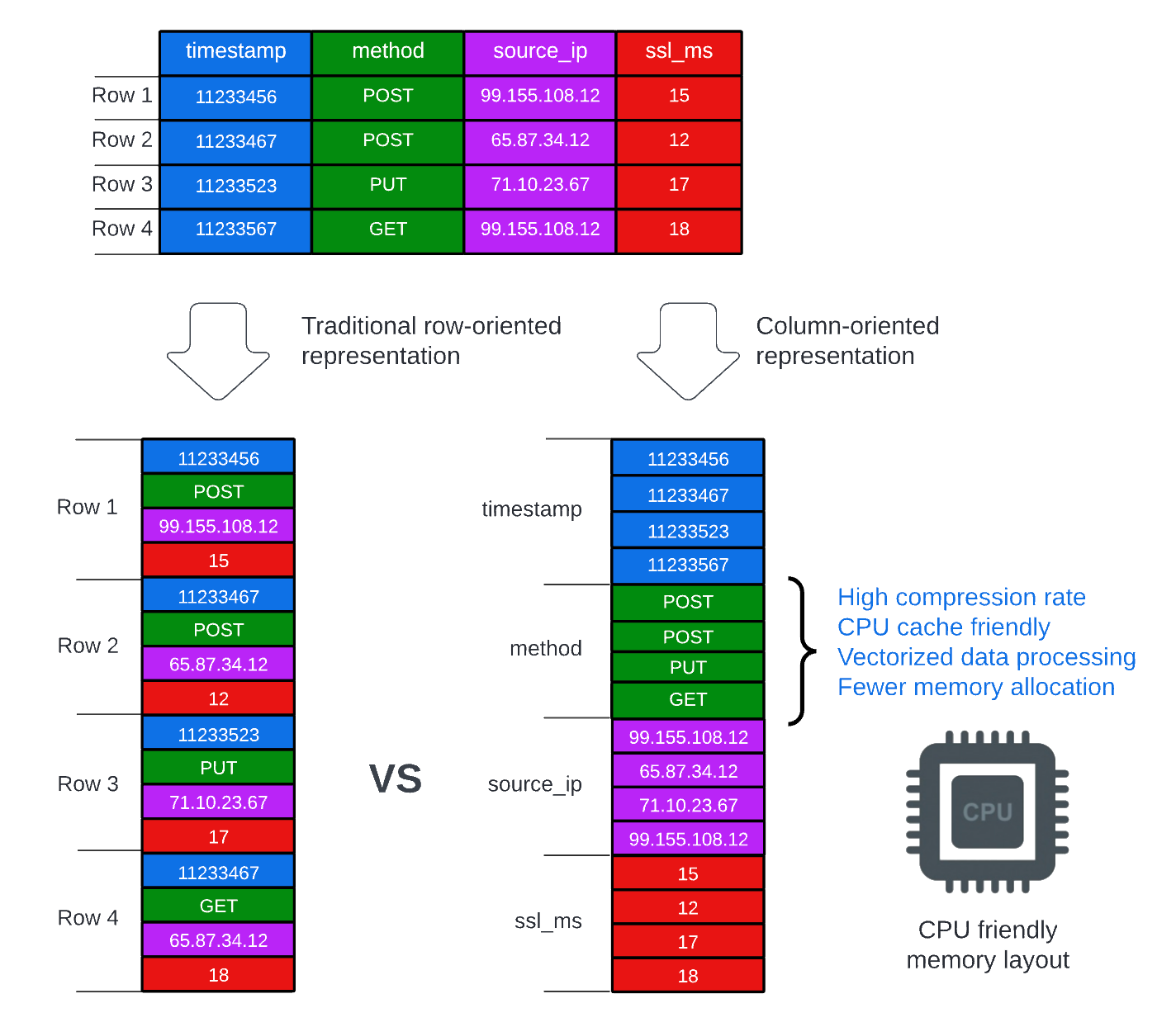
From row-based to column-based systems
The Composable Data Stack takes the unbundling even further
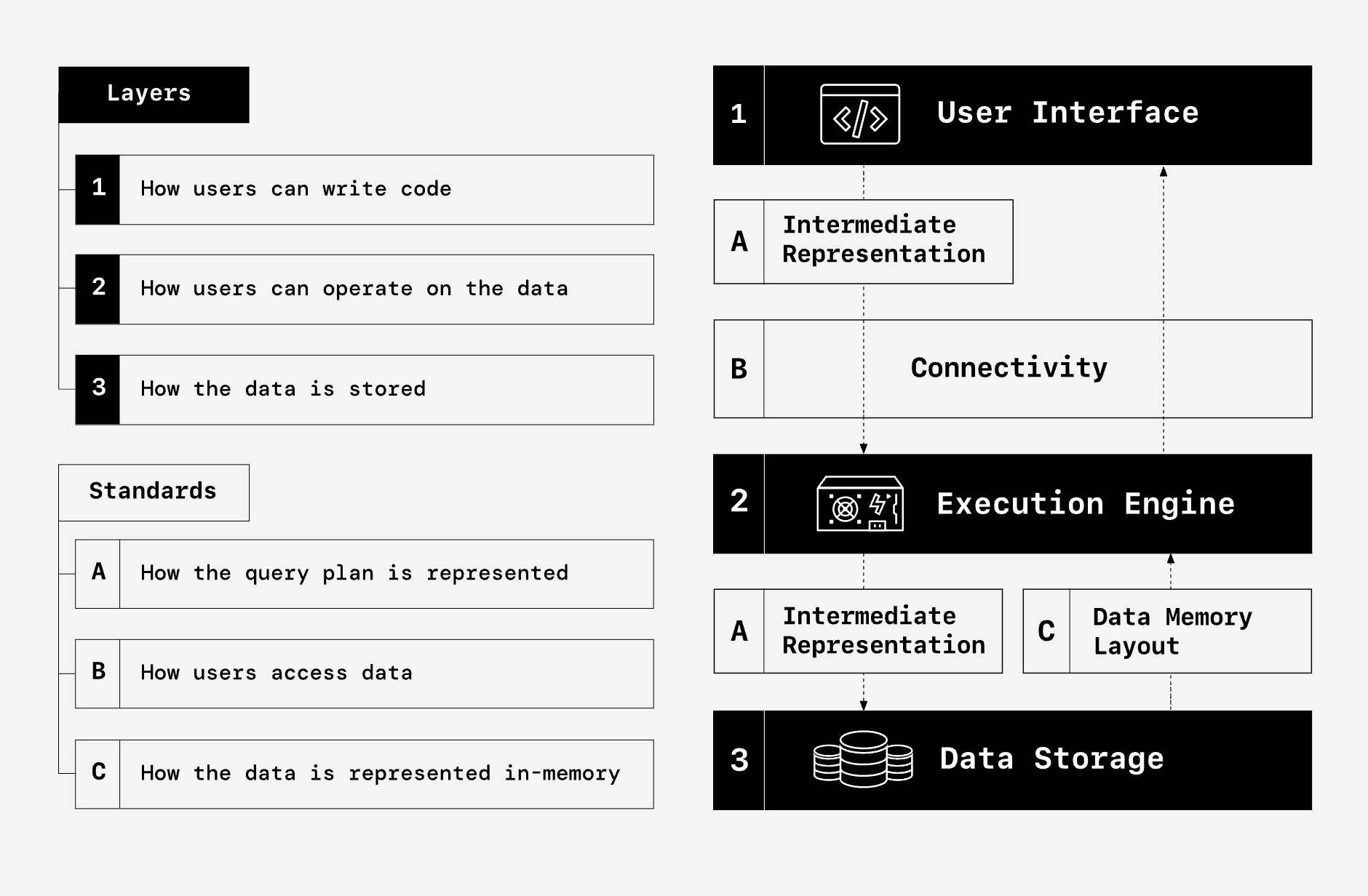
The Composable Data Stack takes the unbundling even further
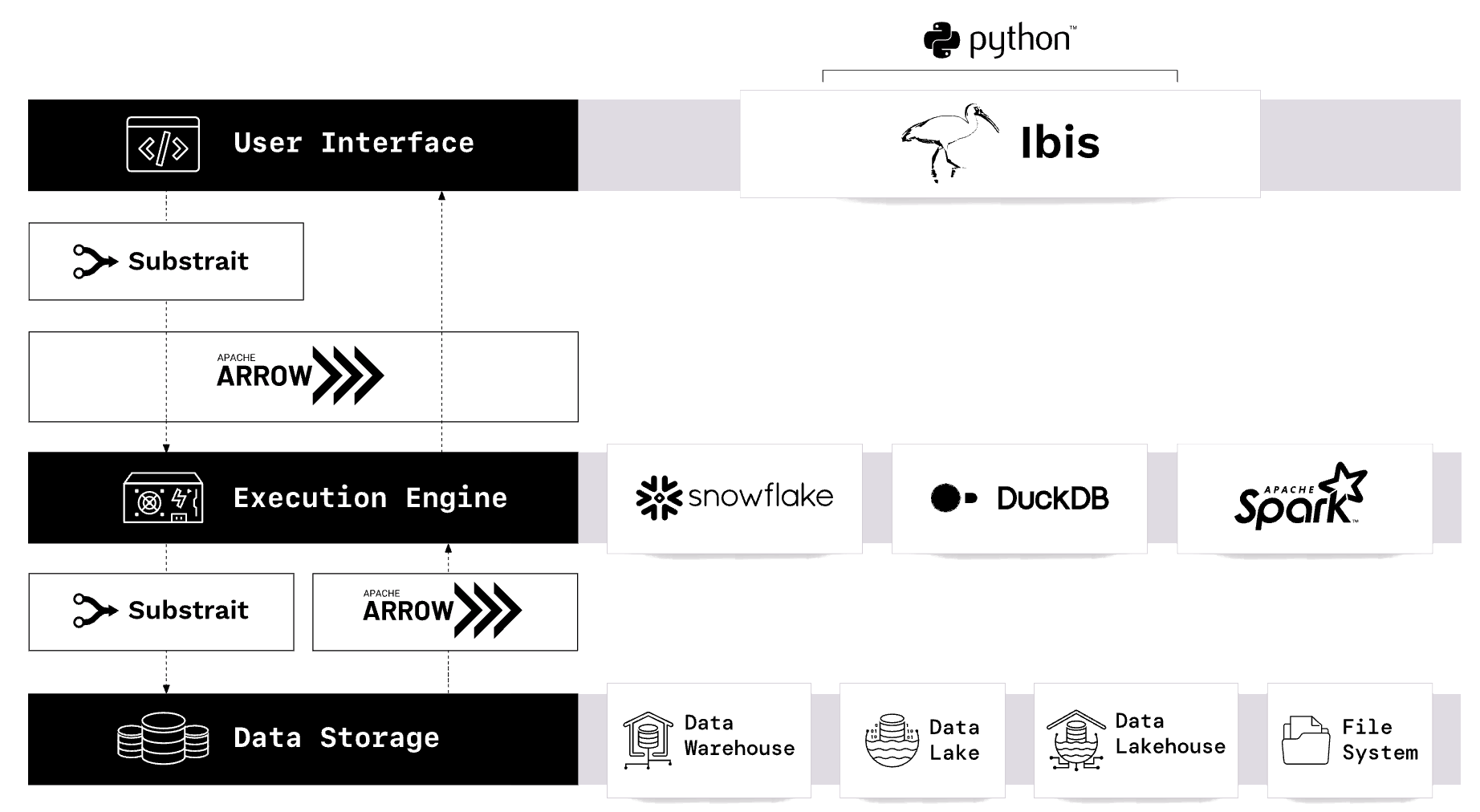
End-to-end columnar data with Apache Arrow ADBC and Flight SQL
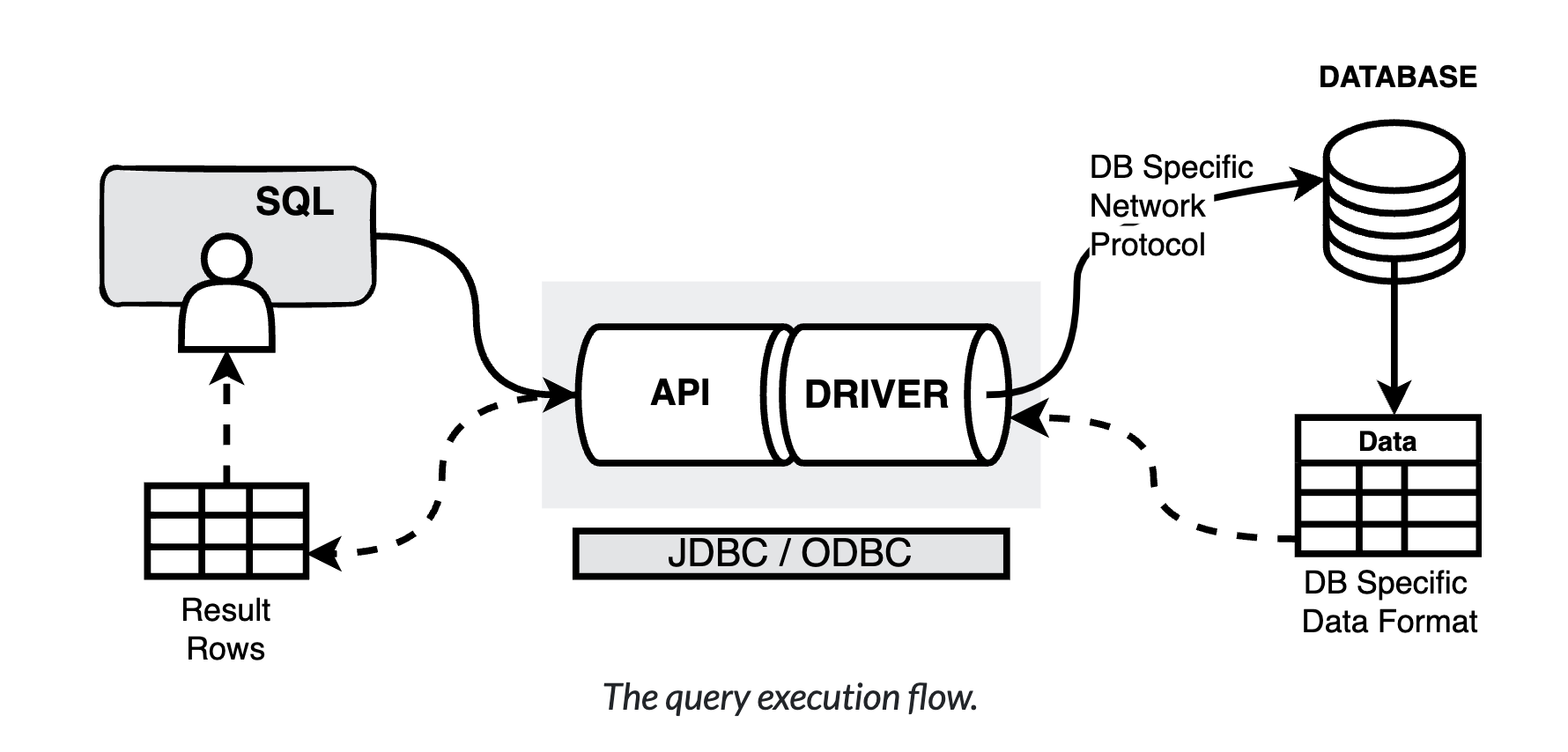
JDBC/ODBC: row-based database connectivity protocols
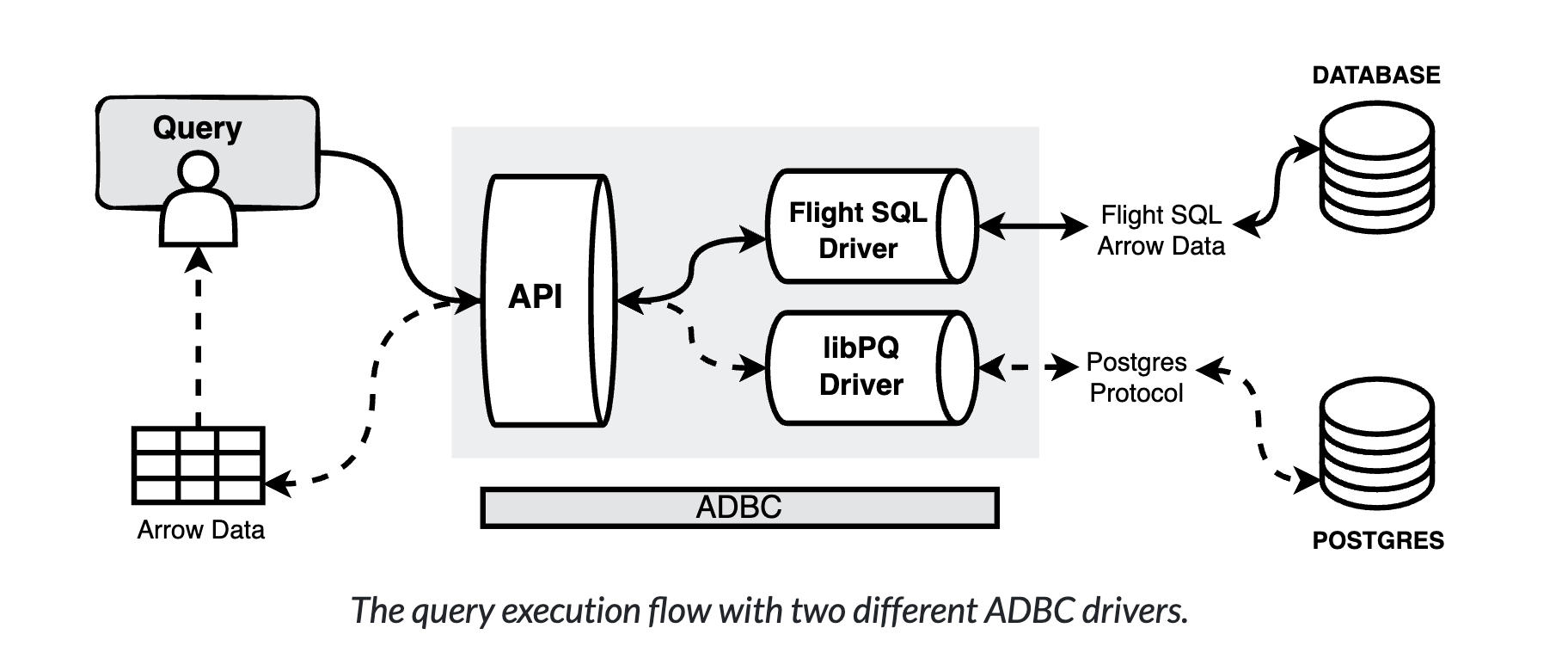
Arrow Database Connectivity (ADBC) is column-based
Iceberg: an open table format and catalog
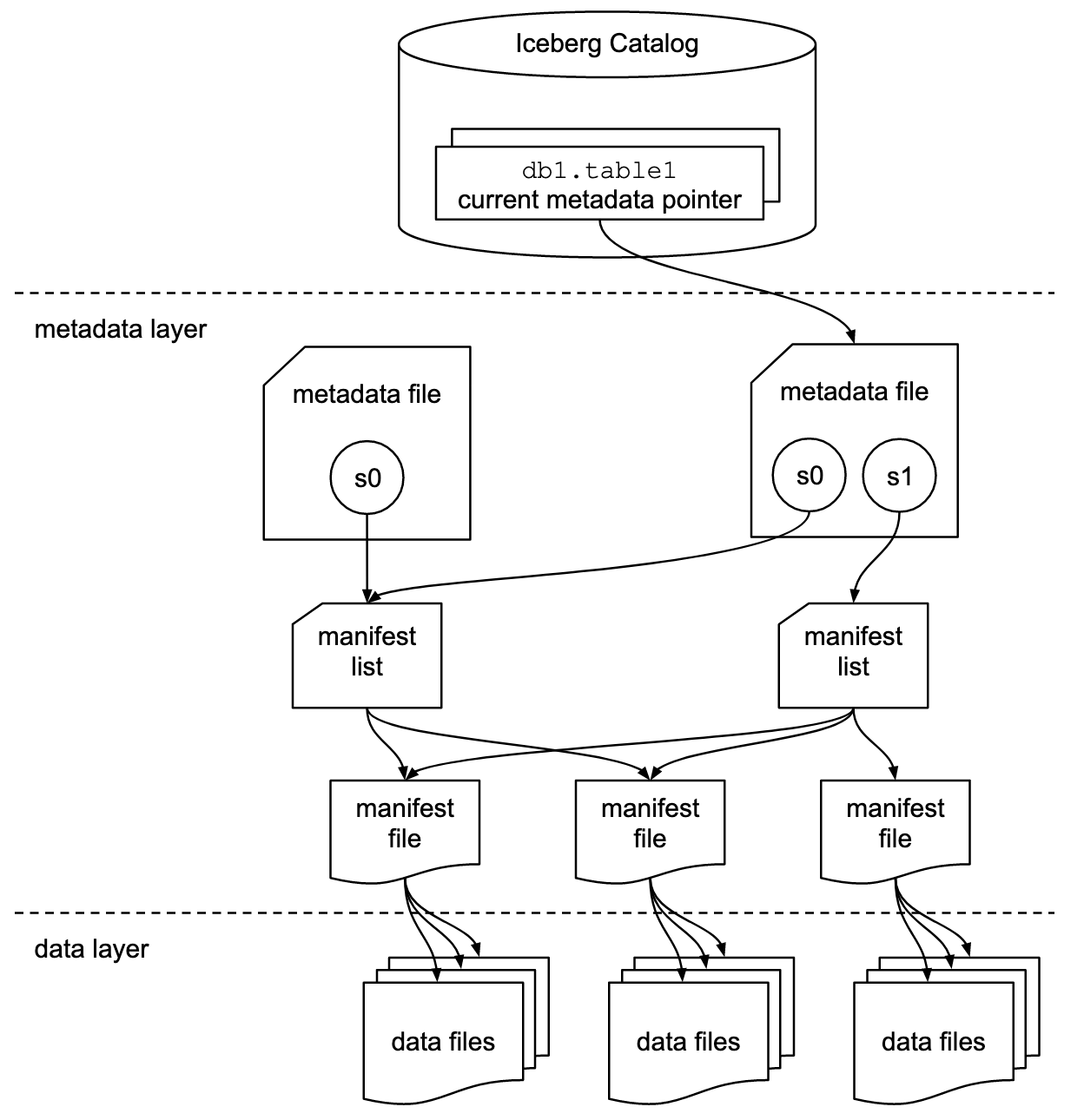
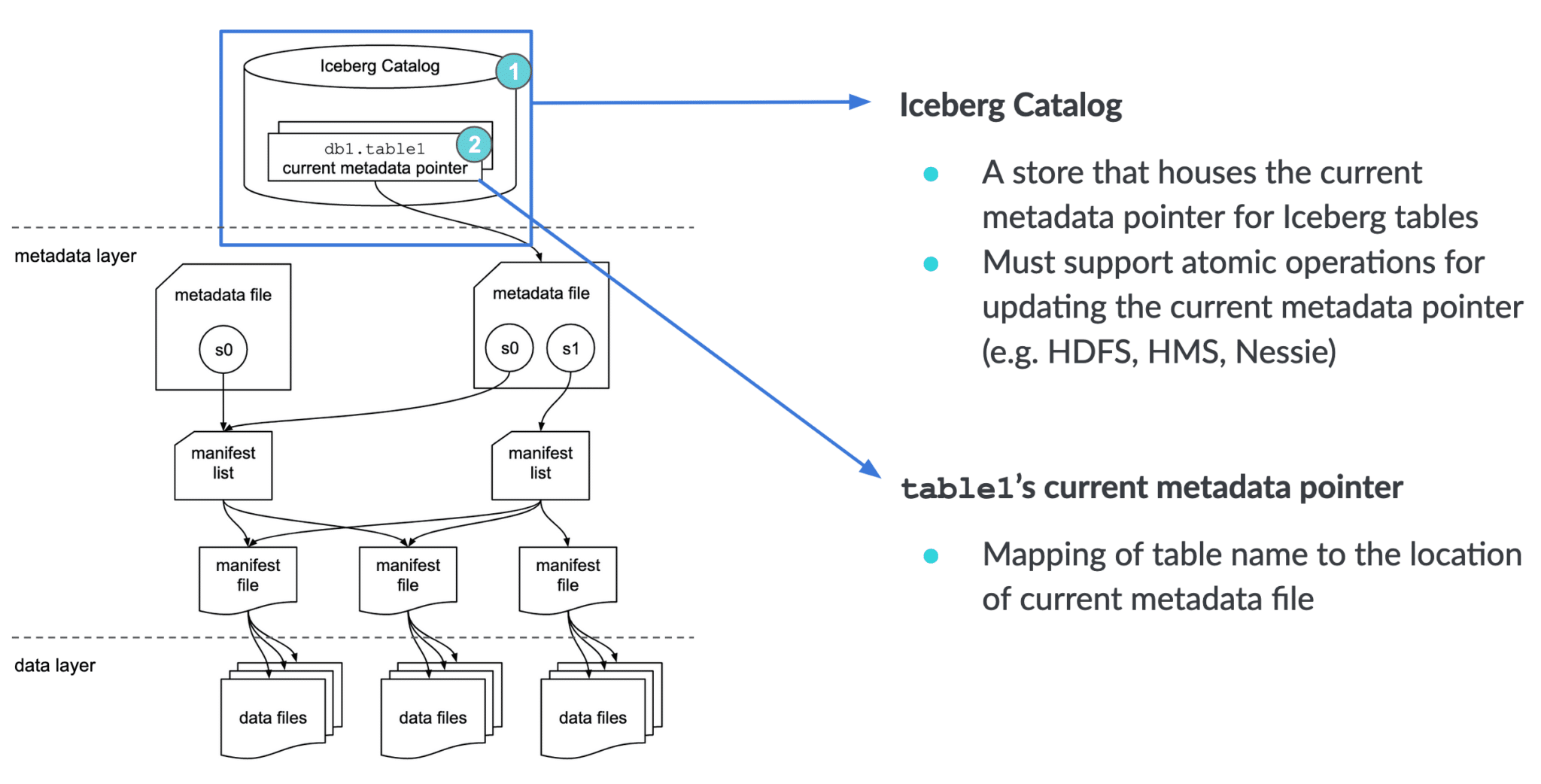
Iceberg catalog
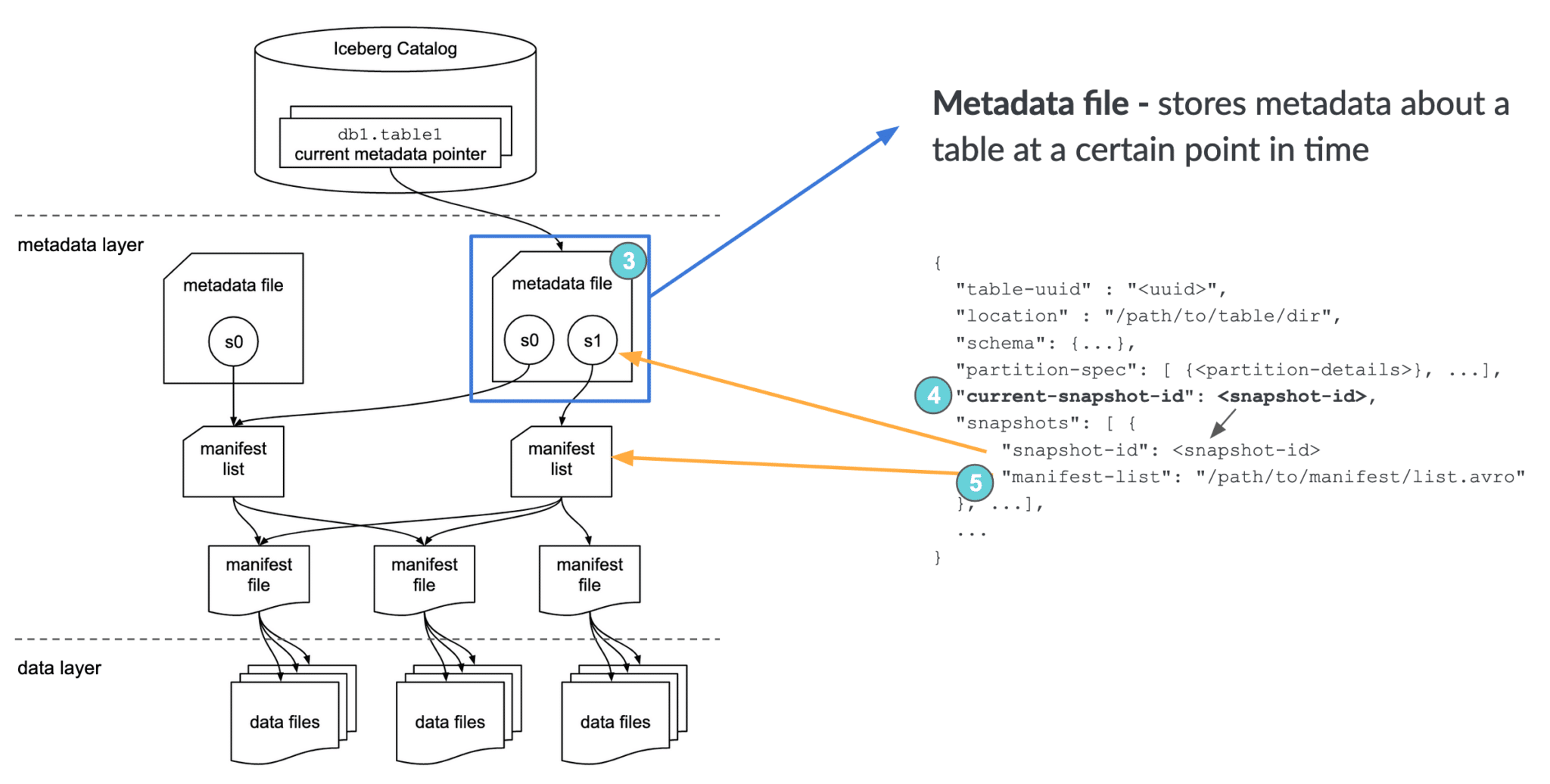
Iceberg metadata file
Big Data Is Dead
So has our dream come true?
We are getting very close …
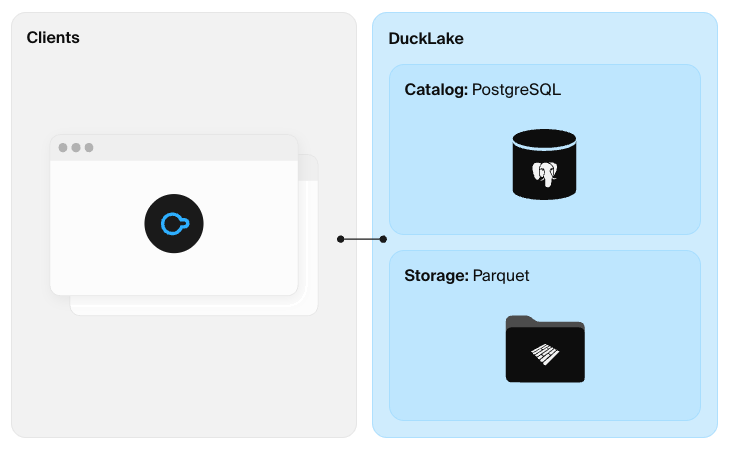
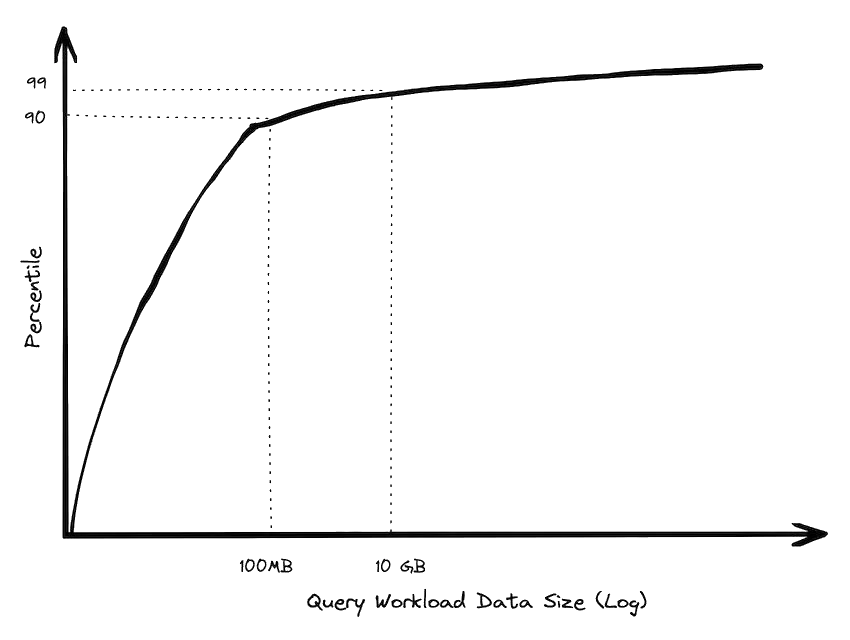
Diagonal scaling of a DuckLake lakehouse
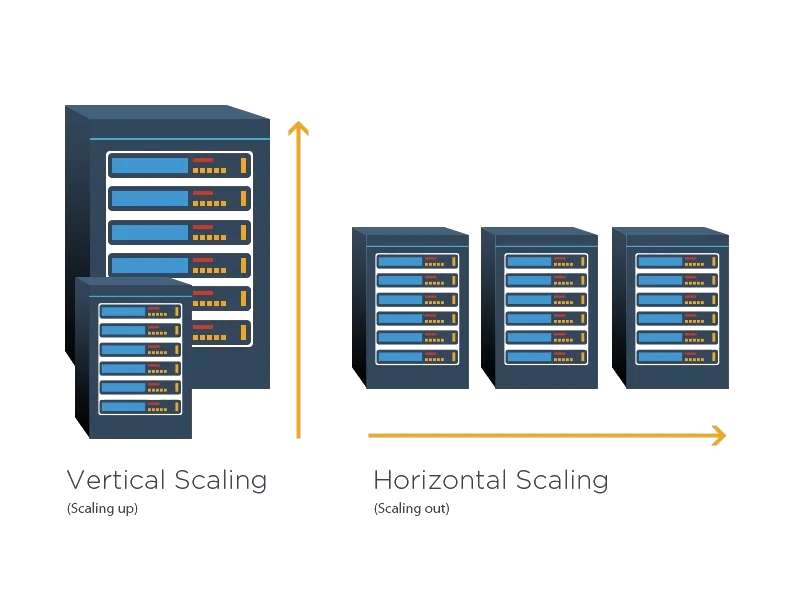
- Vertical scaling of single node query engines that can process up to 100 TB, covering 99% of use cases
- Horizontal scaling of blob storage in (sovereign!) data centres
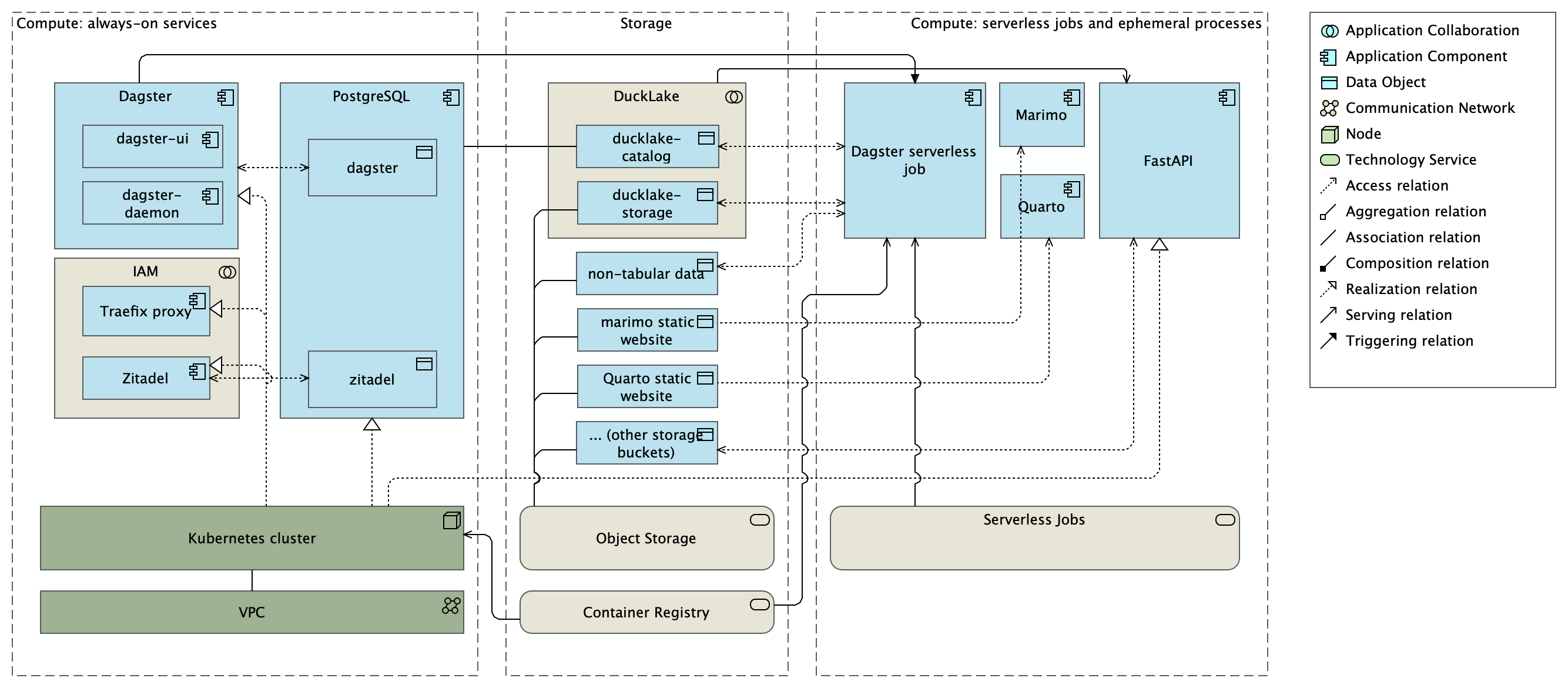
From components to a whole platform architecture
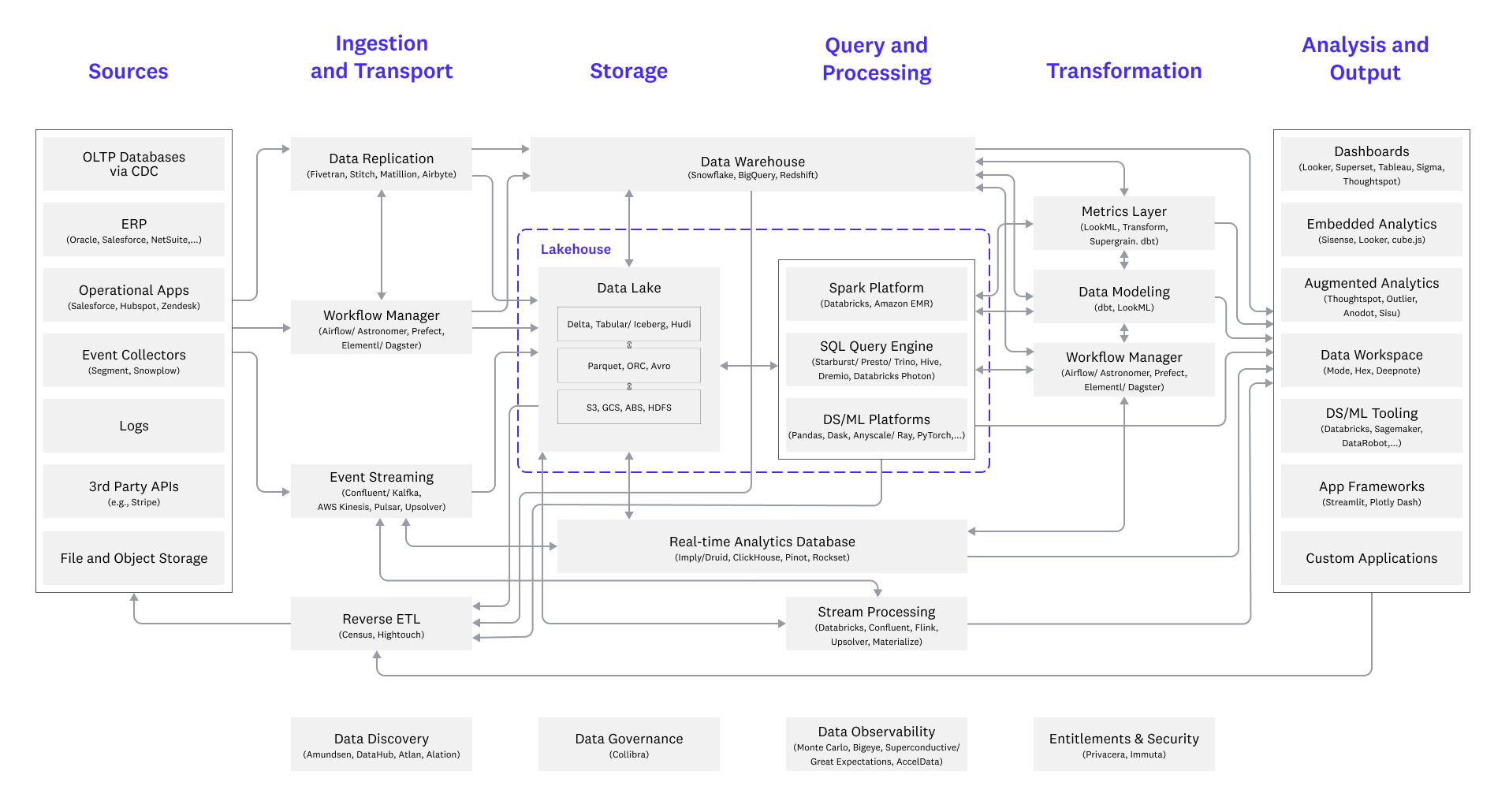
From components to a whole platform architecture
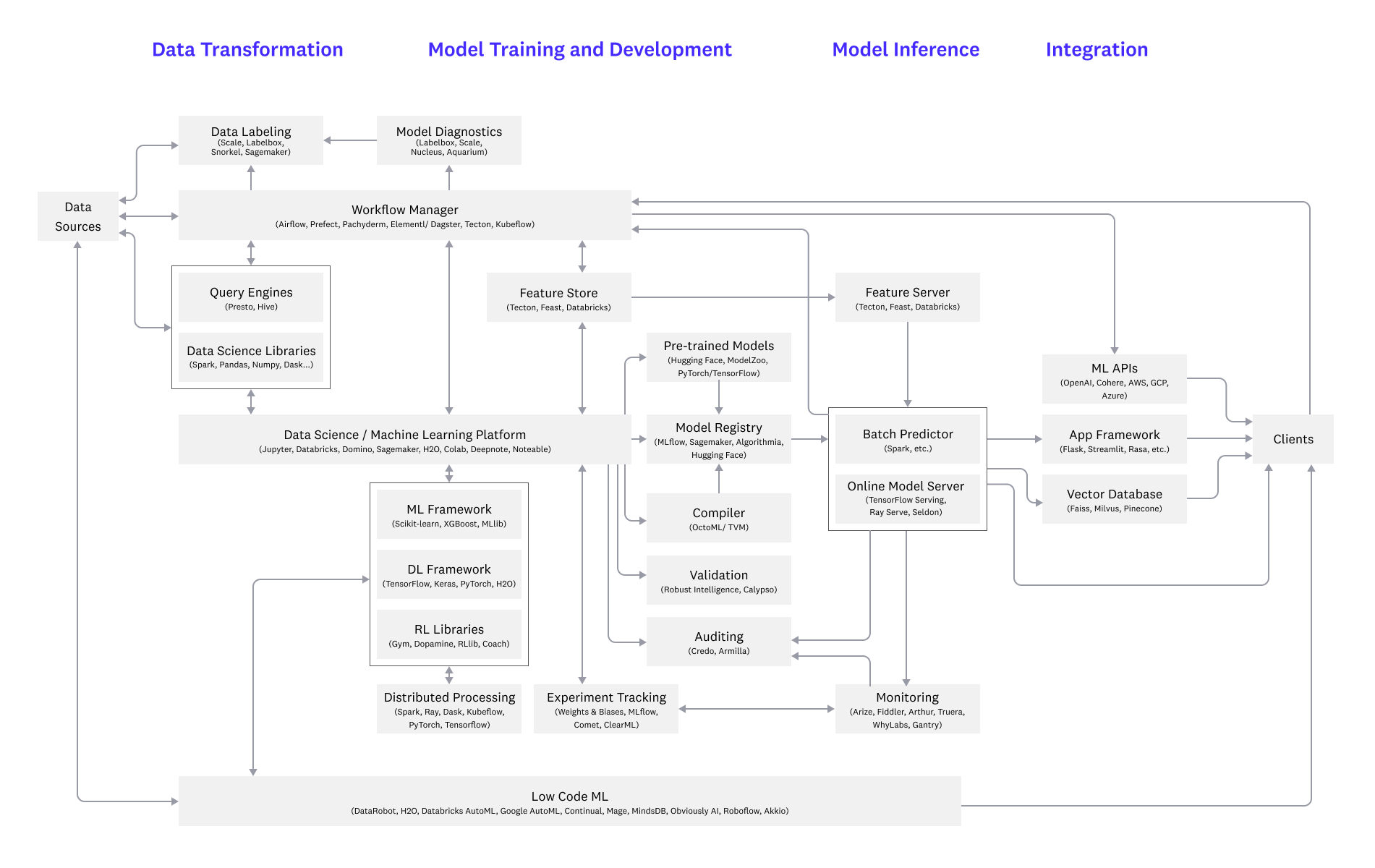
Introducing the Single-Repo Data Platform (SRDP)
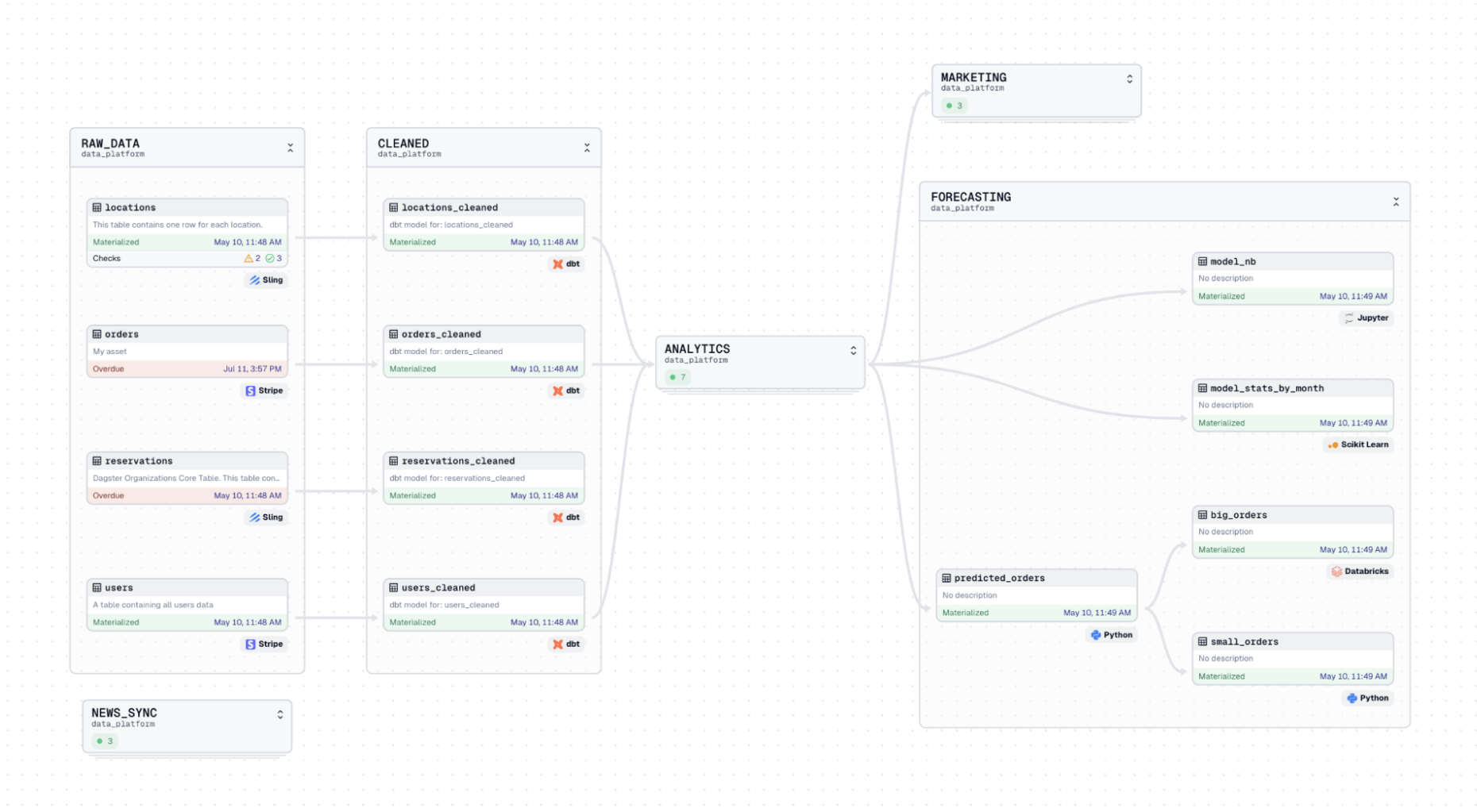
ETL, ELT, DAGs, pipelines, dataflows: it’s all the same
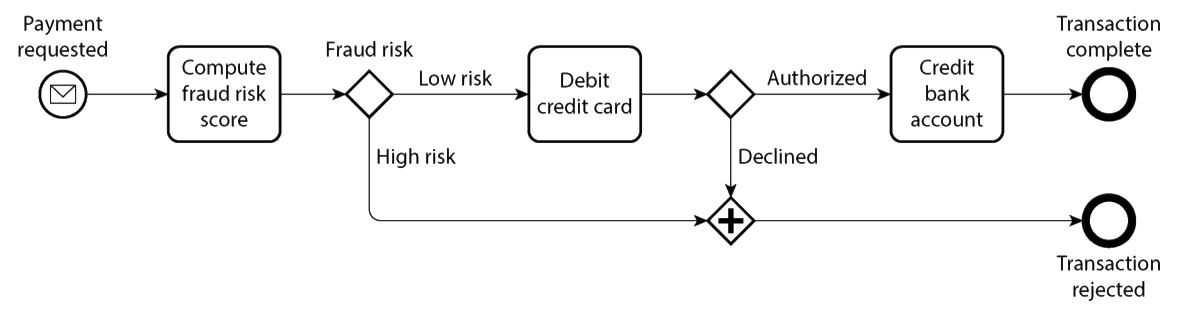
Business process models are also directed acyclic graphs
Batch data processing has a strong functional flavour
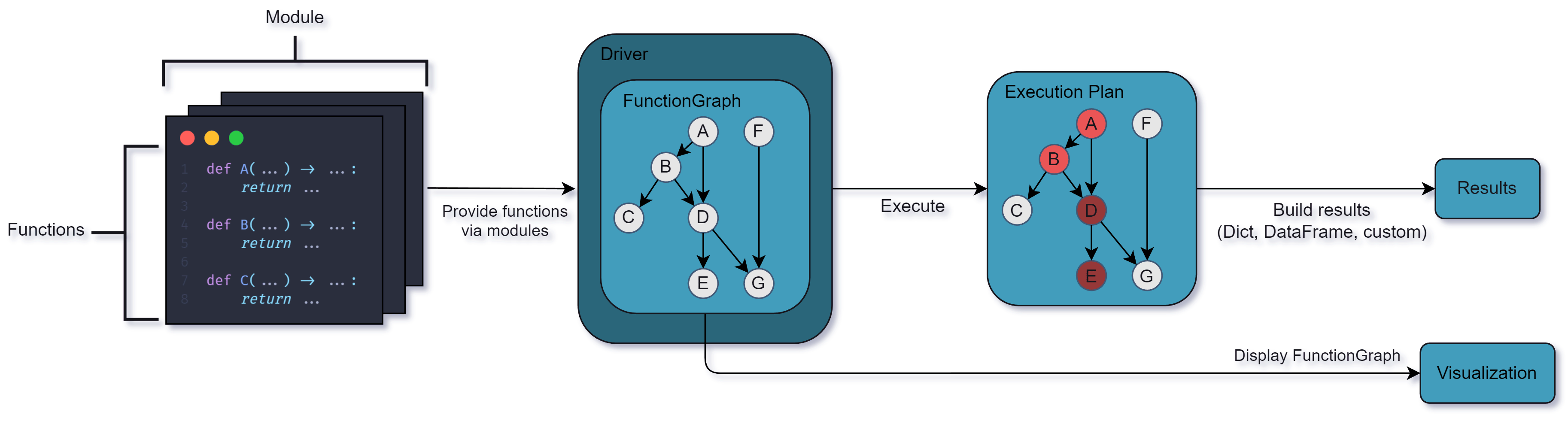
Why functional data engineering?
Immutability, snapshots and partitions
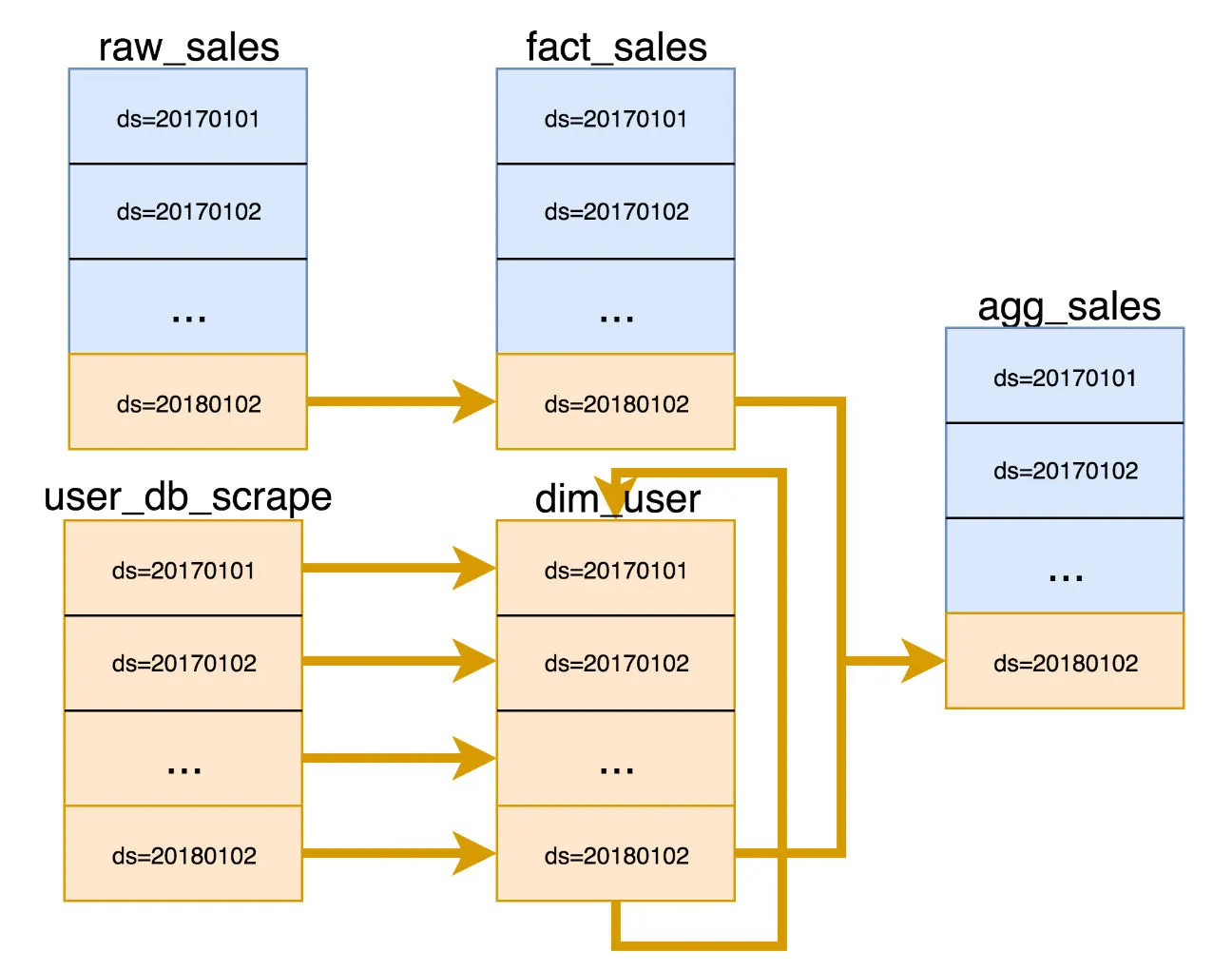
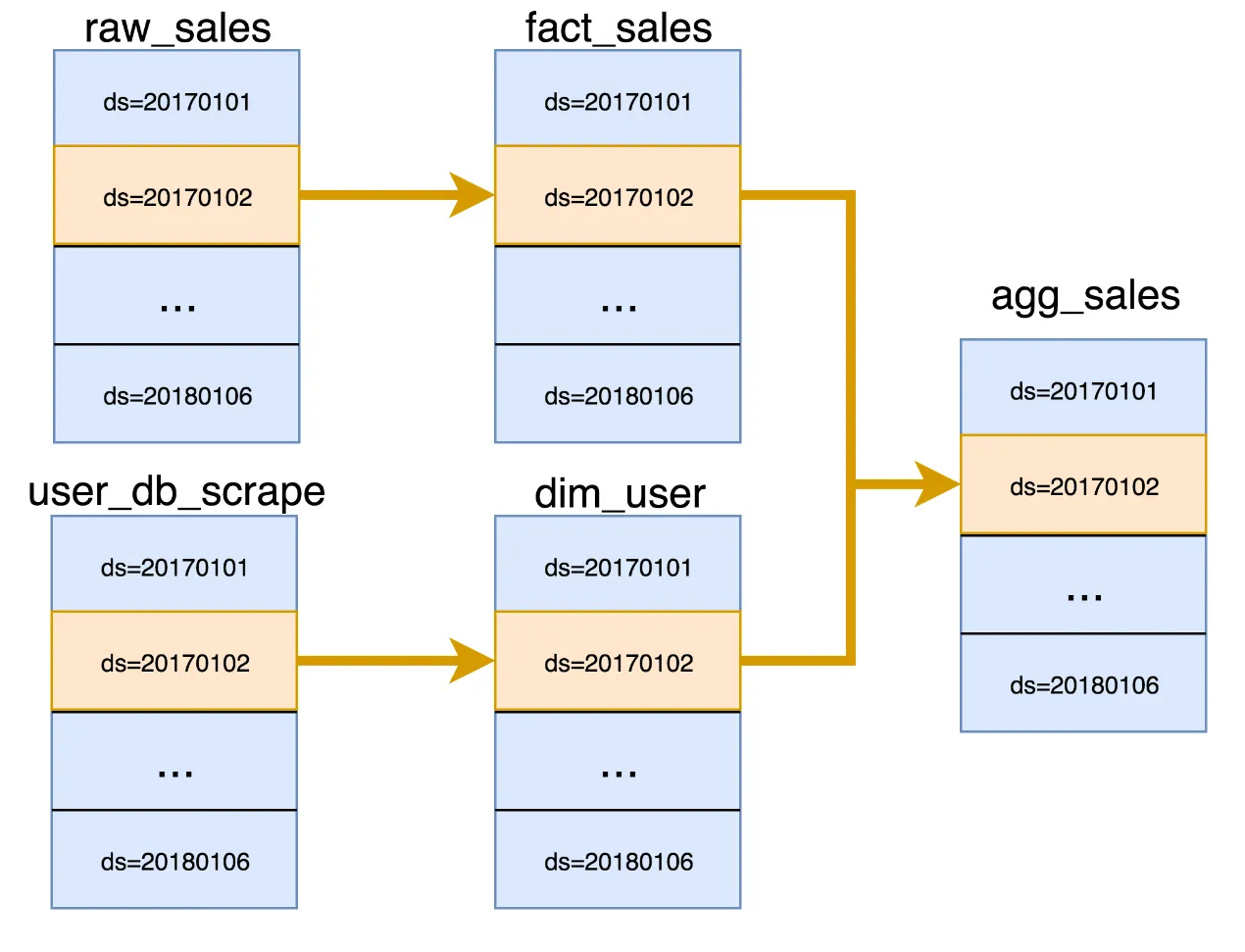
Same approach for machine learning pipelines
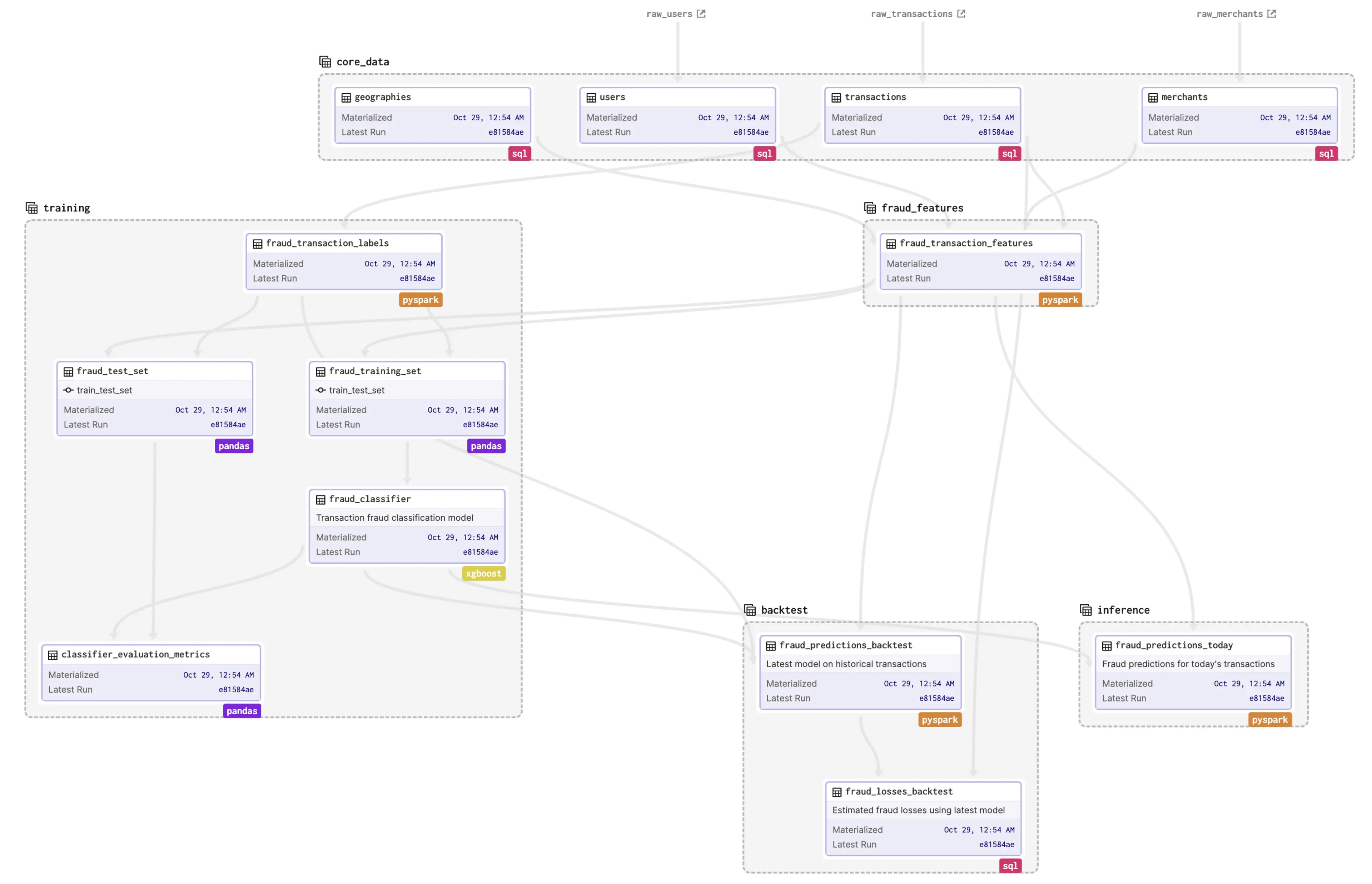
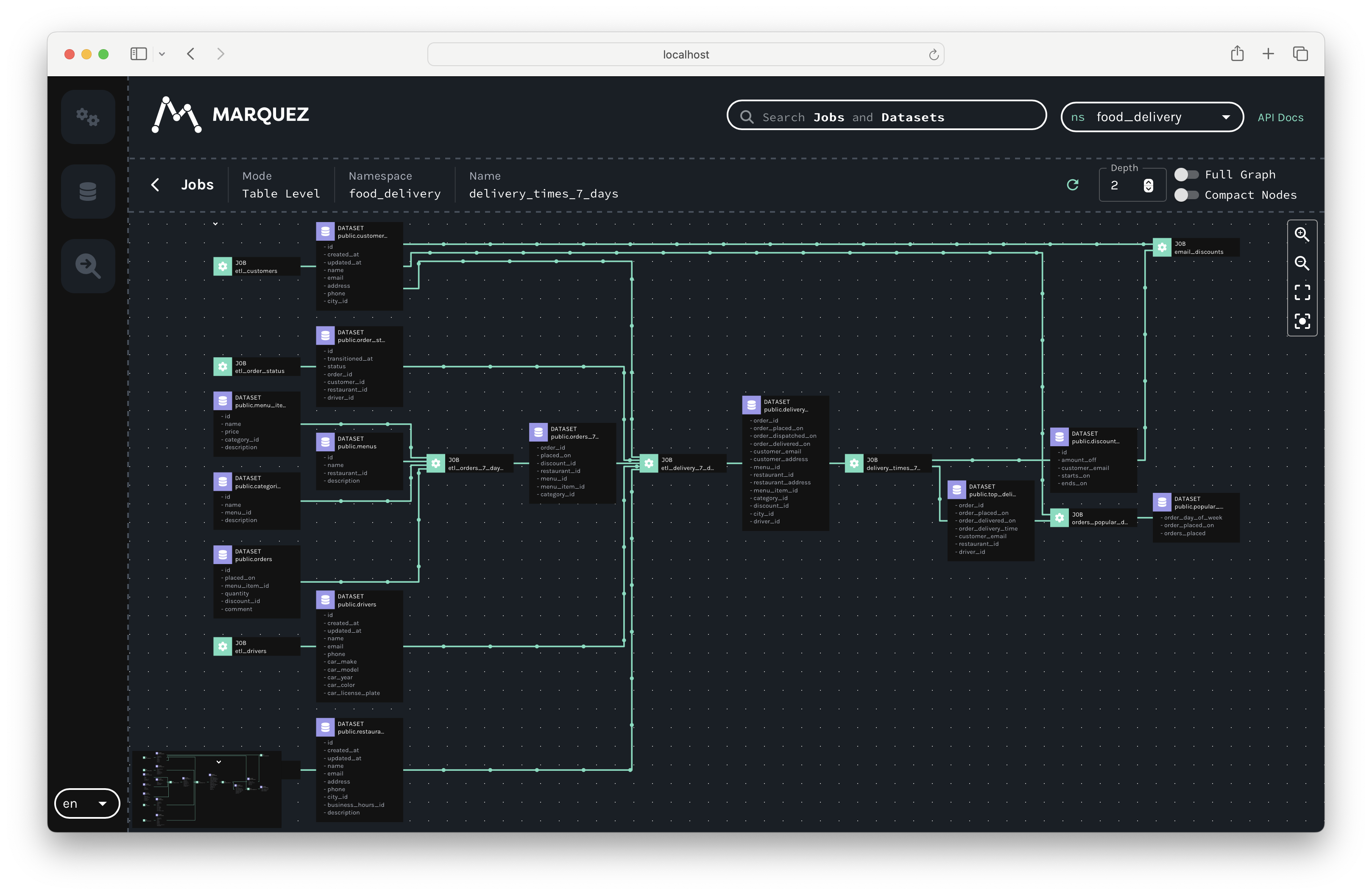
OpenLineage as the standard for metadata collection and data lineage


Marquez is the open source reference implementation of OpenLineage

Stages of machine learning CI/CD automation pipeline
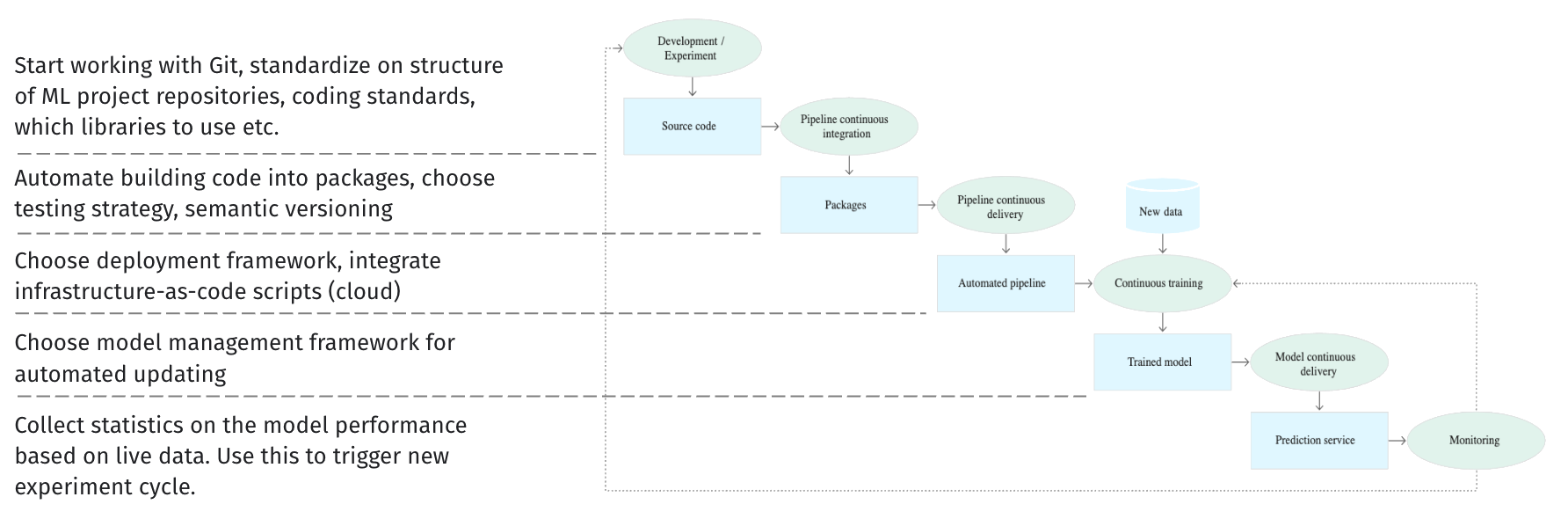
MLOps level 0

MLOps level 1

MLOps level 2

ONNX as the standard for ai interoperability
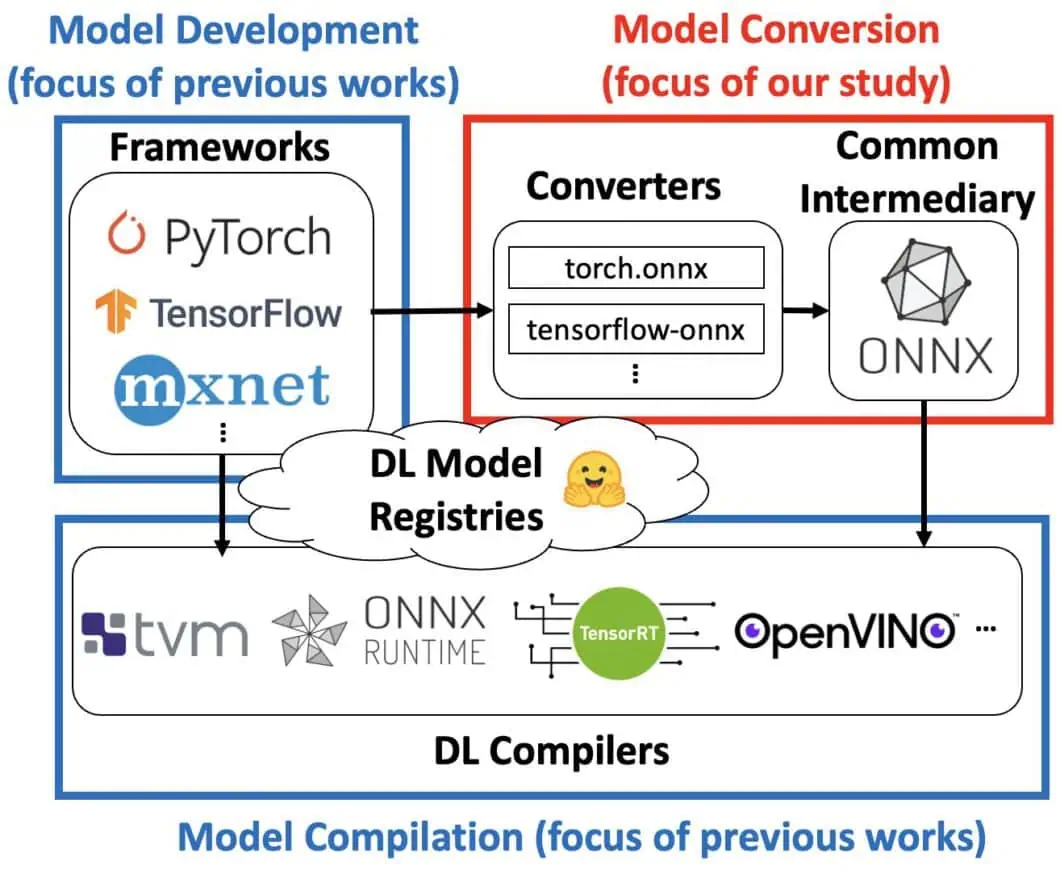
The most complete open source MLOps library

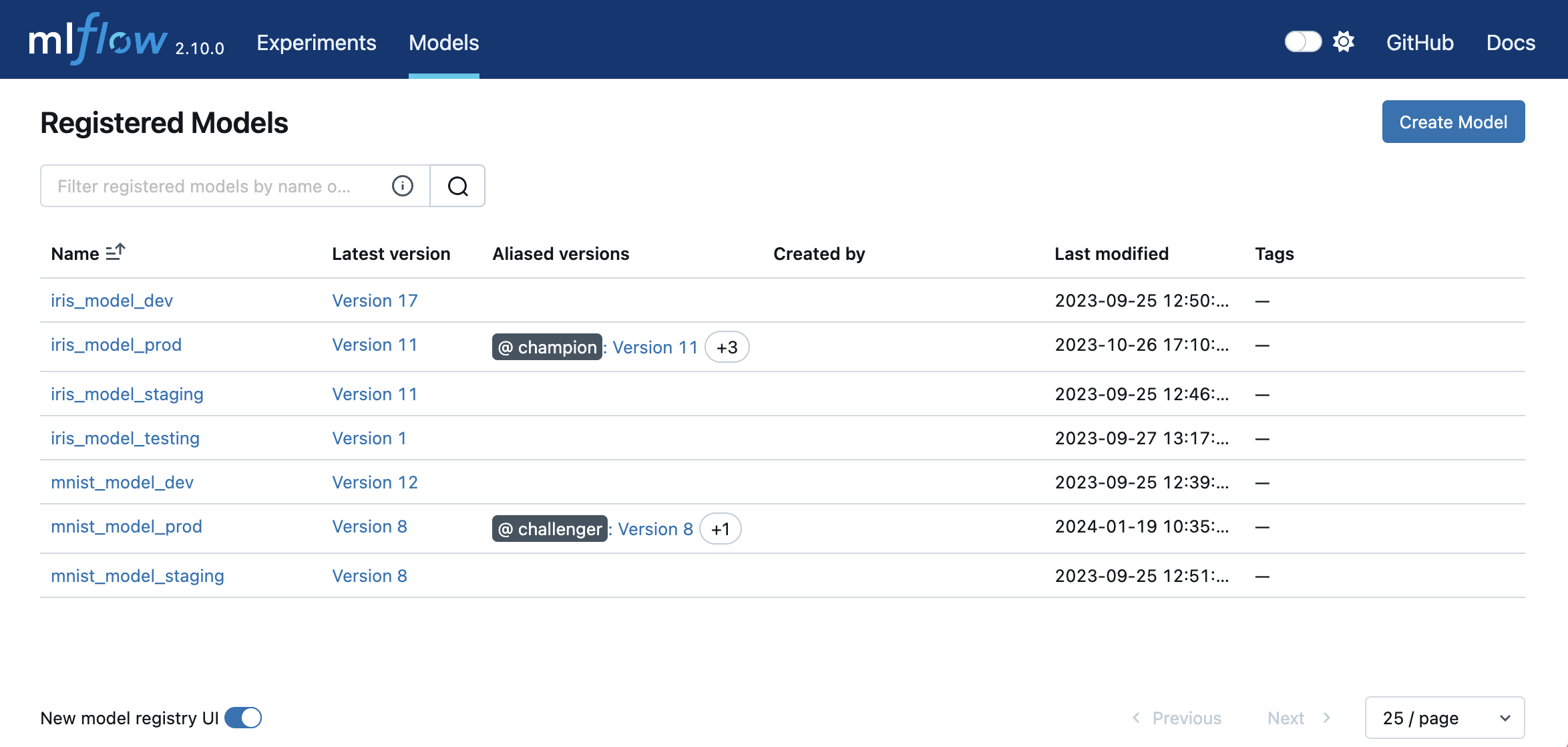
MLflow Tracking & Experiments
MLflow Model Registry
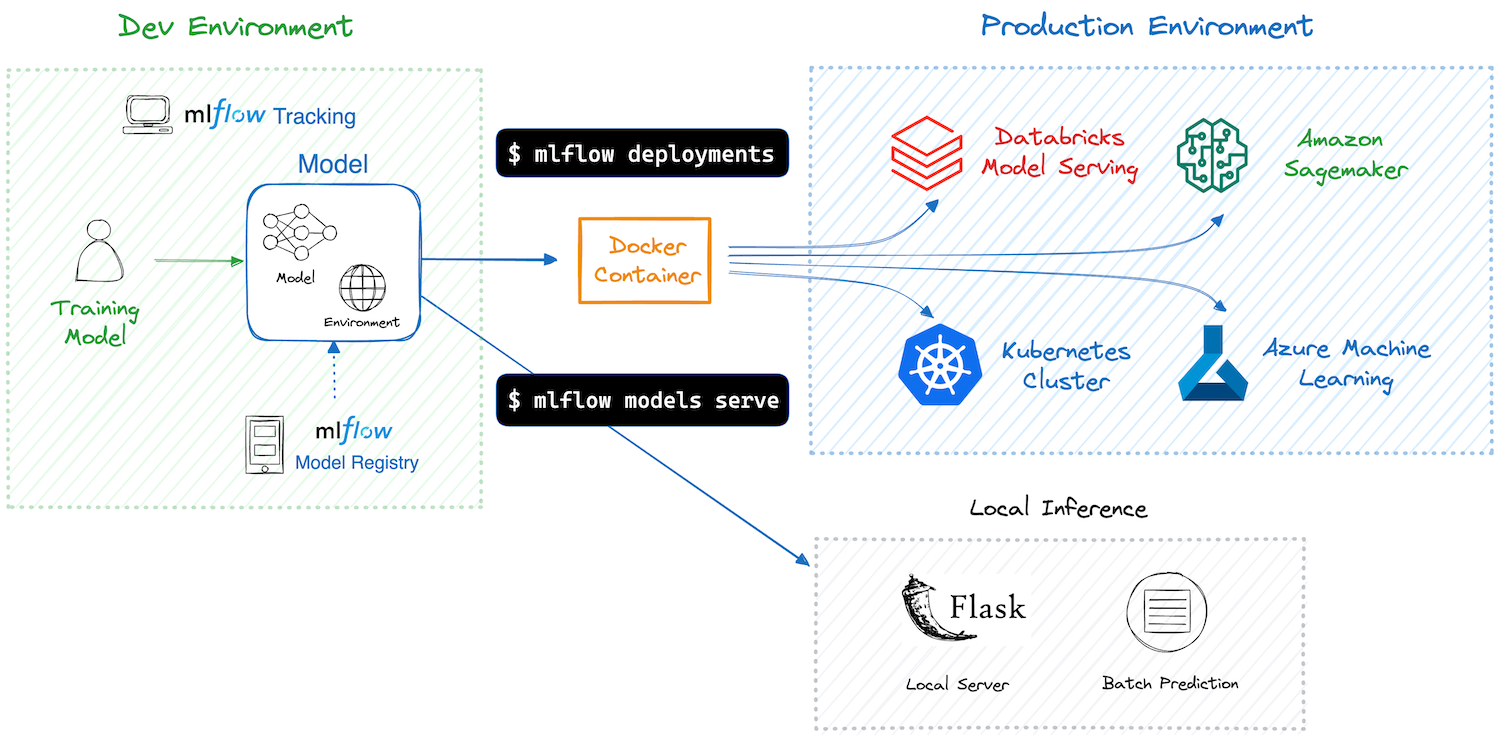
MLflow Model Deployment
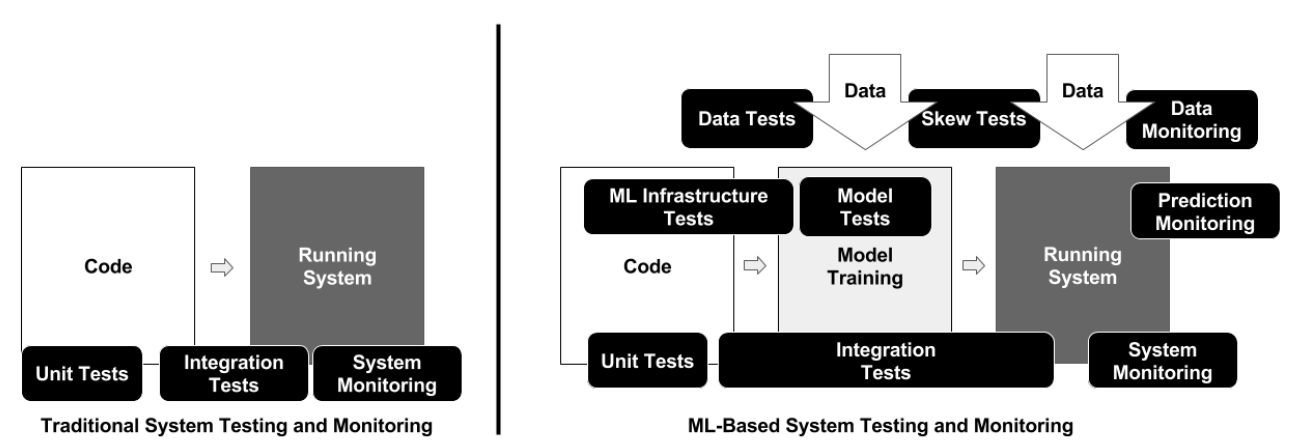
How about testing?
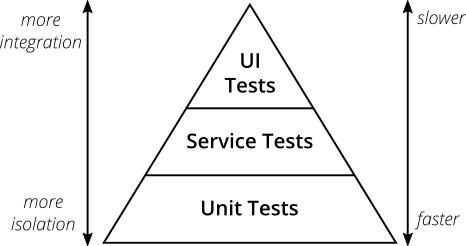
- Write tests with different granularity
- The more high-level you get the fewer tests you should have
How about testing?