| Name | Address | City | Postcode | DOB | Height | Weight |
|---|---|---|---|---|---|---|
| Dustin B. Roach | 1183 Columbia Road | Holly Oak, DE | 19809 | 1970-09-16 | 5' 9" | 202.5 |
| Iwona Adamczyk | ul. Zabłudowska 133 | Warszawa | 04-788 | 1976-01-03 | 5' 5" | 123.7 |
| Geneviève Massé | 1415 rue Principale | Amos, QC | J9T 1E4 | 1967-12-08 | 5' 3" | 136.3 |
| João Souza Lima | Rua Cosmorama, 538 | São Paulo-SP | 04648-080 | 2001-04-21 | 6' 2" | 231.0 |
| Maddison McCabe | 149 Raymond Street | Strathern | Invercargill 9812 | 1982-03-05 | 5' 8" | 146.1 |
The Design Philosophy of Great Tables
visualization
We’ve spent a lot of time thinking about tables. Tables—like plots—are crucial as a last step toward presenting information. There is surprising sophistication and nuance in designing effective tables. Over the past 5,000 years, they’ve evolved from simple grids to highly structured displays of data. Although we argue that the mid-1900s served as a high point, the popularization and wider accessibility of computing seemingly brought us back to the simple, ancient times.
Okay, it’s not all that bad but the workers of data are today confronted with an all-too-familiar dilemma: copy your data into a tool like Excel to make the table, or, display an otherwise unpolished table. Through the exploration of the qualities that make tables shine, the backstory of tables as a display of data, and the issues faced today, it’s clear how we can solve the great table dilemma with Great Tables.
Tables made with computers (left to right): (1) a DataFrame printed at the console, (2) an Excel table, and (3) a Great Tables table.
What is a table, really?
Before getting to what makes tables shine we should first define what a table is. This is surprisingly hard! But I believe it can be boiled down to two basic rules:
- the data is represented as columns and rows
- the data is primarily text
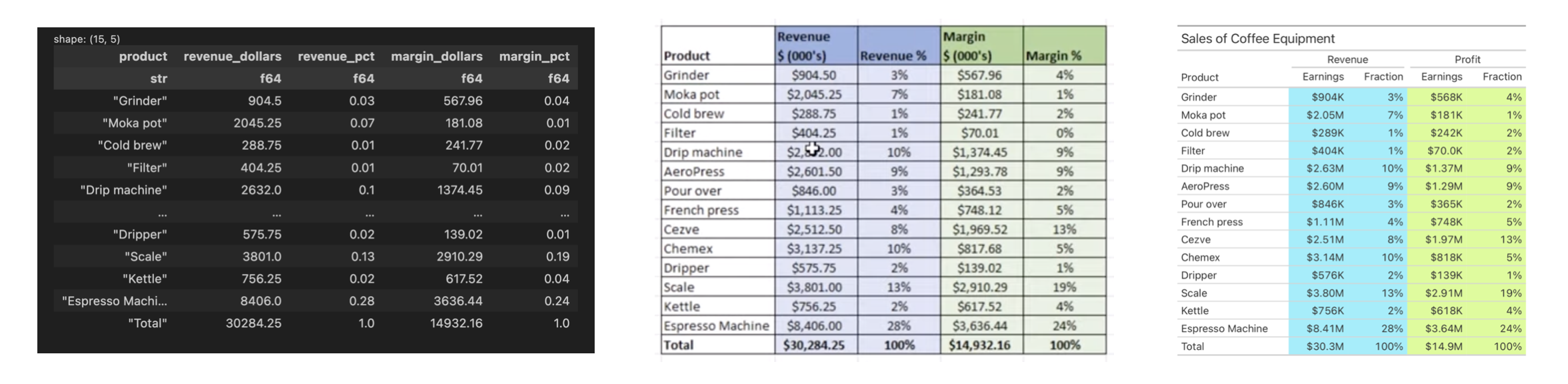
Let’s look at an example of a simple table with actual data to tie this theory to practice.
A table of named individuals along with a select set of characteristics.
This table arranges records containing personal characteristics as columns and rows. Each person is a row, and each characteristic makes up a different column. The characteristics use different types of data, like dates, numbers, and text. This arrangement makes it easy to look up individual values or make comparisons across the different rows or columns.
Note that there are horizontal lines separating the rows. This aesthetic touch, while not strictly required for a table, serves as a visual reinforcement for separating the individual rows.
The order of the columns matters, and that we start with the Name column here is no accident. If that column were the last (i.e., furthest to the right), it would be slightly more confusing for the reader since the subject for the record isn’t immediate. In addition to order, column labels play an important role for indicating what data is in each column. They’re not always necessary but in most cases they remove the guesswork for what type of data is contained within each column.
We’ll go into some detail later about how Great Tables provides affordances for structuring information for better legibility and how the package can be used to adorn the table with other structural elements. For now, our conception of a table can be summarized in this schematic.
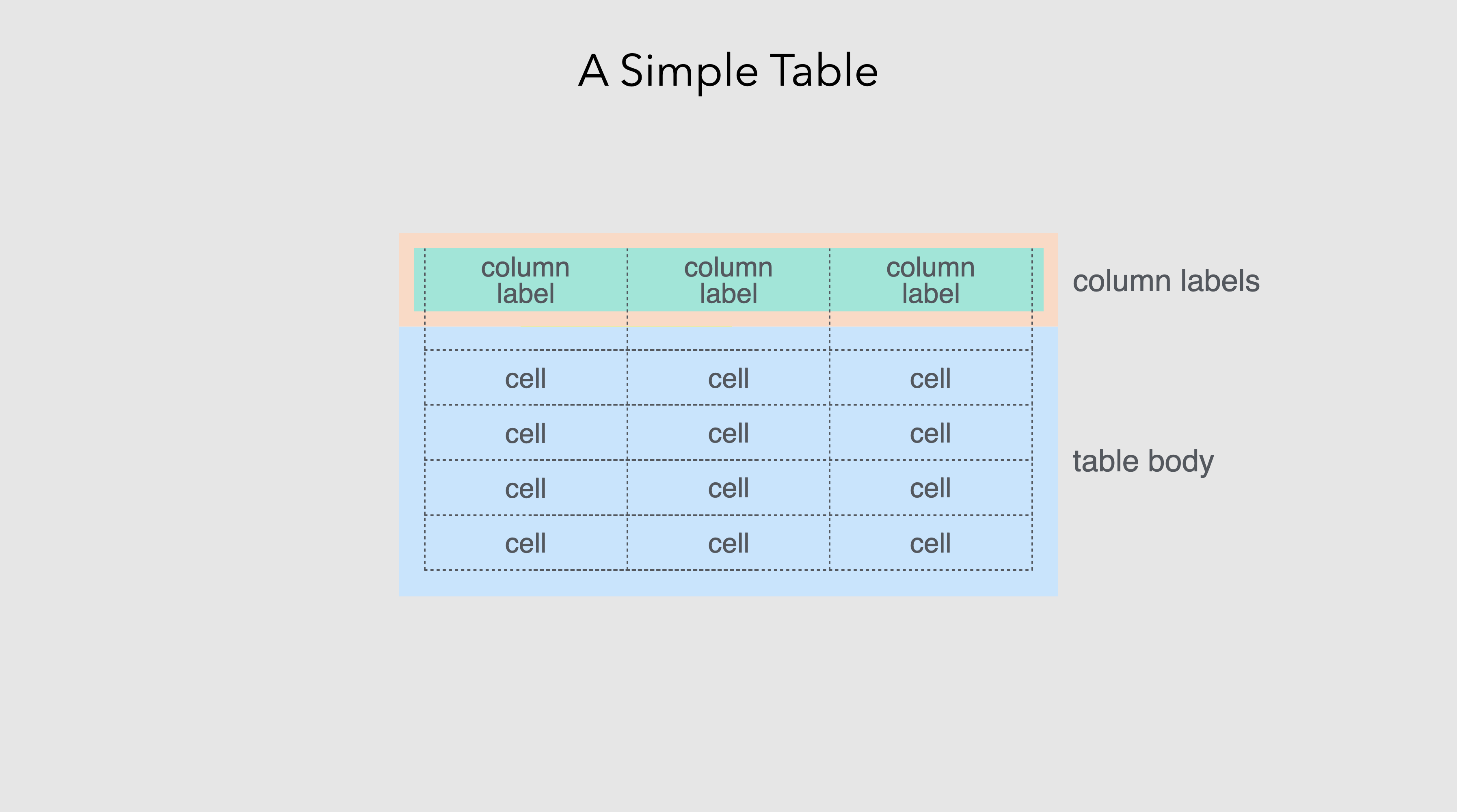
A simple table has: (1) cells containing data, (2) an arrangement of columns and rows, and (3) column labels to describe the type data in each column.
Now, let’s go back: way back. In examining where tables came from, we might better understand the great story of tables.
The early history of tables
Tables emerged from square grids. When grids are made like this, you invariably generate containers that may hold some sort of information. The earliest known examples of grids go very far back in human history. Twenty-five thousand year old representations of the grid are found on the walls of the Lascaux and Niaux caves in France1.

Reproductions of early grids found on cave walls.
In the second century BC, the Greek astronomer Hipparchus used latitude and longitude to locate celestial and terrestrial positions2. At around AD 150, Ptolmey published Geographia, which contains 25 geographical maps accompanied by methodologies for their construction using grids3. The Romans employed a grid system called centuriation, which can be described as land measurement (using surveyors’ instruments) to realize the formation of square grids using roads, canals, or agricultural plots4.
When agriculture became more widespread (ca. 10,000 years ago), there was the need to document and manage economic transactions to do with farming, livestock, and the division of labor. In the fourth millennium BC, Mesopotamian cities that traded with far way kingdoms needed to keep such records. Clay tablets recovered from the ancient Sumerian city of Uruk show early yet sophisticated tables. Here is a drawing of one of the recovered tablets, which contains an accounting of deliveries of barley and malt from two individuals for the production of beer5.
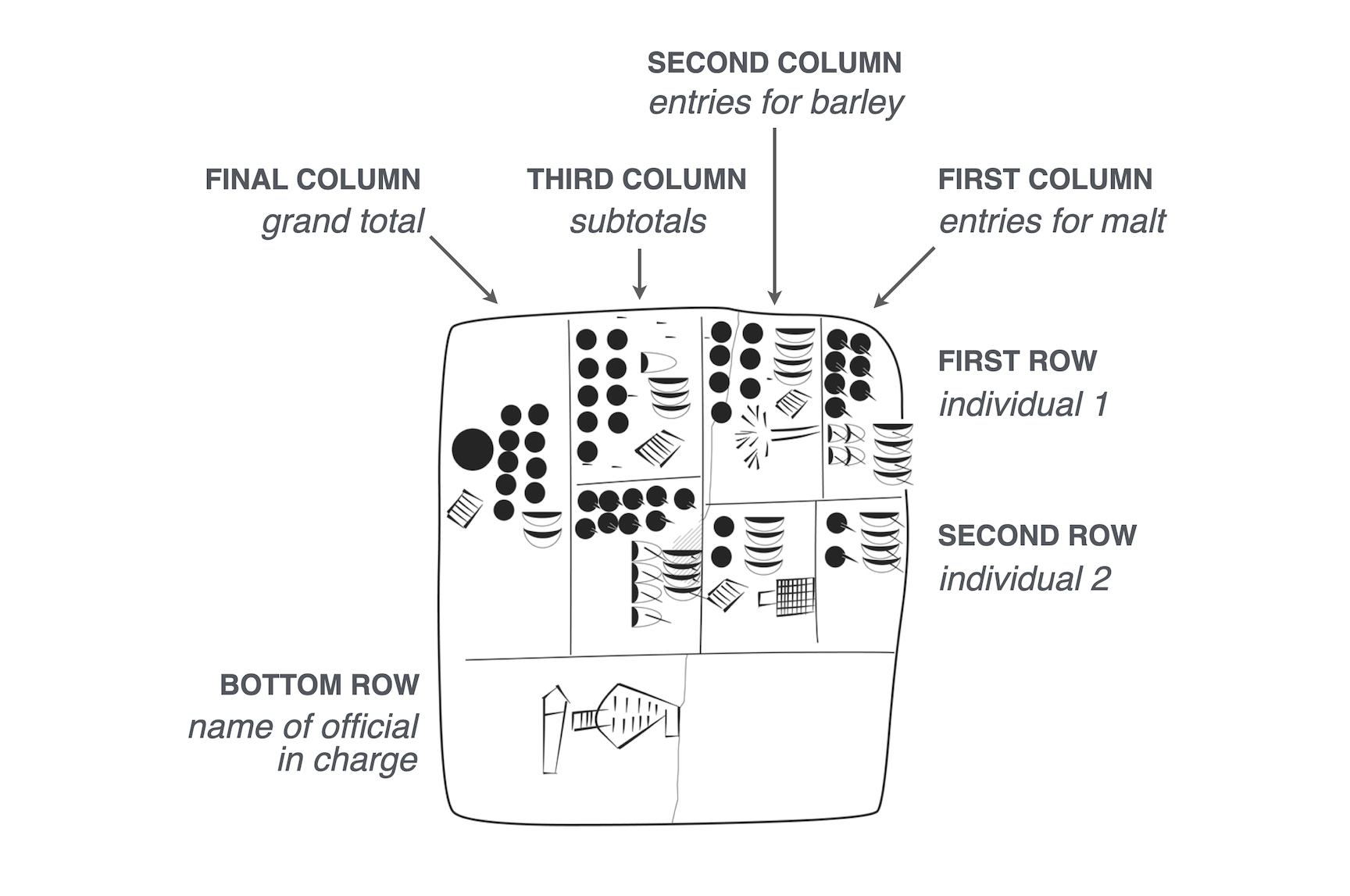
Drawing of clay tablet from Sumerian city of Uruk, circa 3200-3000 BC. Uruk III Tablet (MSVO 3, 51, Louvre Museum, Paris, France). Annotated with the meanings of the columns, rows, and cells.
Note that the recovered tablet is meant to be read from right to left. Inside each box is an ideogram (a symbol that represented a word or idea) and a numerical value representing a quantity.
Its structure is where things get super interesting:
- Rows: there are roughly two rows, each corresponding to an individual.
- Columns: the first two columns from the right contain counts of malt (rightmost column) and barley (second rightmost column).
- Subtotals: the third column from the right sums barley and malt within each individual, and the left-most column displays the grand total.
As a bonus, the table has a footer, since the bottom row contains the name of the official in charge.
Zooming ahead about a thousand years, you start to see more systematically structured tables. Here’s a photo of a cuneiform tablet that was originally from Mesopotamia (from the Temple of Enlil at Nippur, ca. 1850 BC)6, containing sources of revenue and monthly disbursements for 50 temple personnel.

Cuneiform tablet, temple of Enlil at Nippur, (CBS 3323, University of Pennsylvania).
You can see right away that there is a more regular grid and, if you probe deeper, there are more similarities than differerences with the tables of today. While difficult to pick them out, the following table elements are present7:
- column headings (month names) and row titles (names/professions of individuals).
- cells with no information (look at the blank or smooth cells along rows)
- numerical values in the cells
- subtotals for each individual every six months
- grand totals
- annotations with explanatory notes
Later on, tables were less inscribed on clay and more on wax tablets, papyrus, and paper. The media have changed, writing technologies have changed, and the design and presentation of tables also went through changes.
Midcentury modern tables
Perhaps the best period for tables was around the middle of the 20th century. Technologies for table (and surrounding document) preparation included the offset printer, the typewriter, and varitype8 (my favorite). The technologies were sufficiently advanced as to allow the precise typesetting of table elements. While of course constrained by the limited space available on pages, tabular design at this point had many workable solutions for fitting tables into single pages or dispersing the tabular content across multiple pages. The combination of advanced printing technology with advanced knowledge of tabular design resulted in beautiful tables.
There’s no greater embodiment of that pairing of technology and design than the Manual of Tabular Presentation9, written and published by the United States Bureau of the Census. It is truly a remarkable work which goes into great detail on how the department imagines the ideal designs of information-rich tables. The work articulates the different parts of a table (and each part is given a descriptive name), sparing no detail when describing those different table parts in rigorous detail. Throughout its hundreds of pages, the authors make strong recommendations on what to do (and what not to do) for many tabulation scenarios. When poring over the tables visually depicted in the book, you can’t help but see that tables can both look really good and contain a density of information. The promise and the result is a balance of form and function.
We at Great Tables borrow liberally from this work because many of its tabular design principles are just as good now as they were back then (and we’ll talk about what we took from that work in the next section). We’ll end this brief section with a visual montage of snippets from the Census Manual, which provides a glimpse of the sound advice on offer.
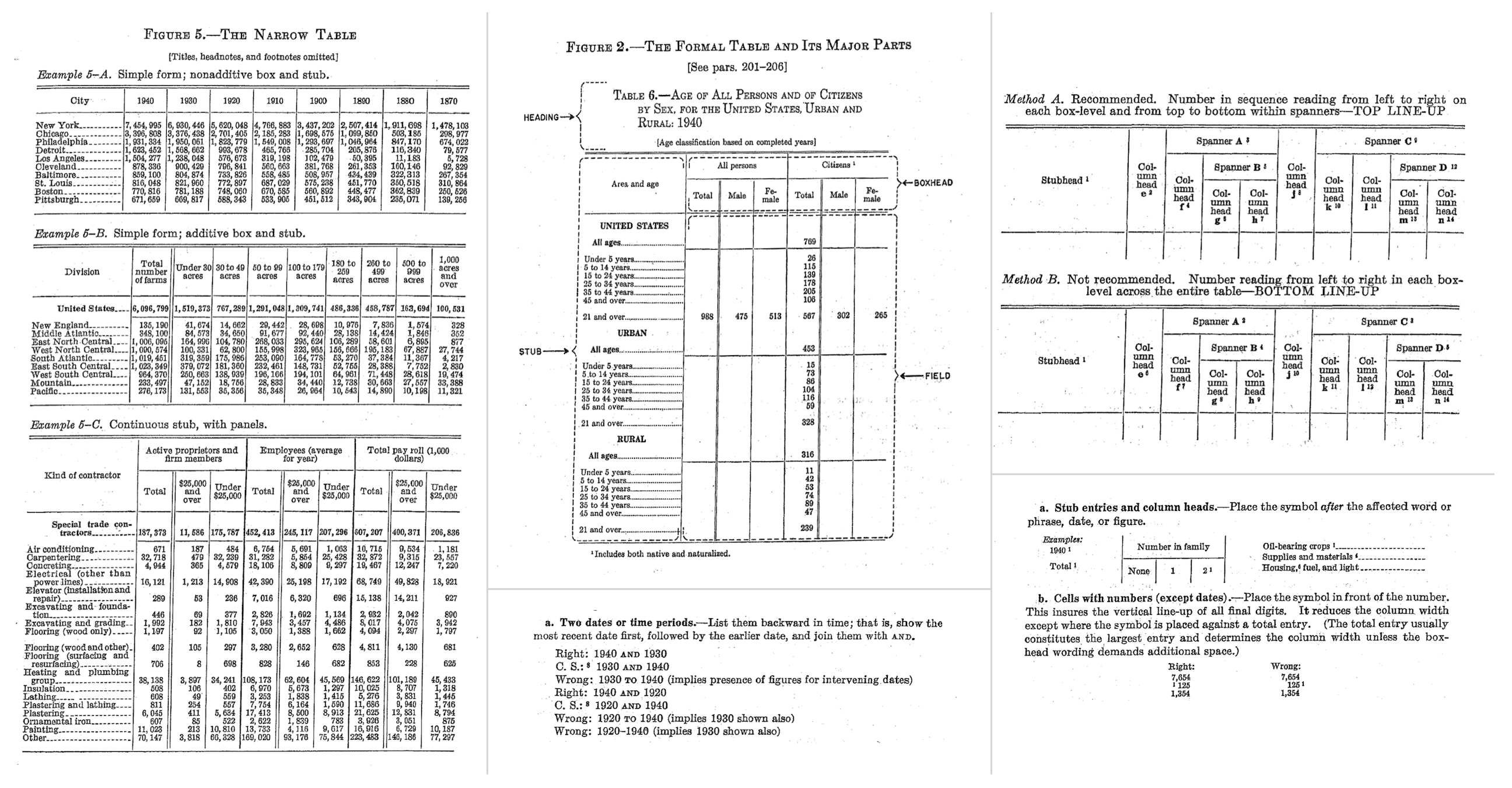
Little nuggets of wisdom from the Census Manual. This may very well be the ultimate book on tabular design.
The late history of tables
With computing technologies becoming more accessible by the 1970s and 1980s, people were able to generate tables in both electronic and print form. The democratization of computational tables arguably began with VisiCalc in 1979, a massive success that initiated the computing category of spreadsheeting software. There’s an undeniable advantage to having data analyzed and transformed in computing environments, but, this comes at a cost. This is what it looked like:
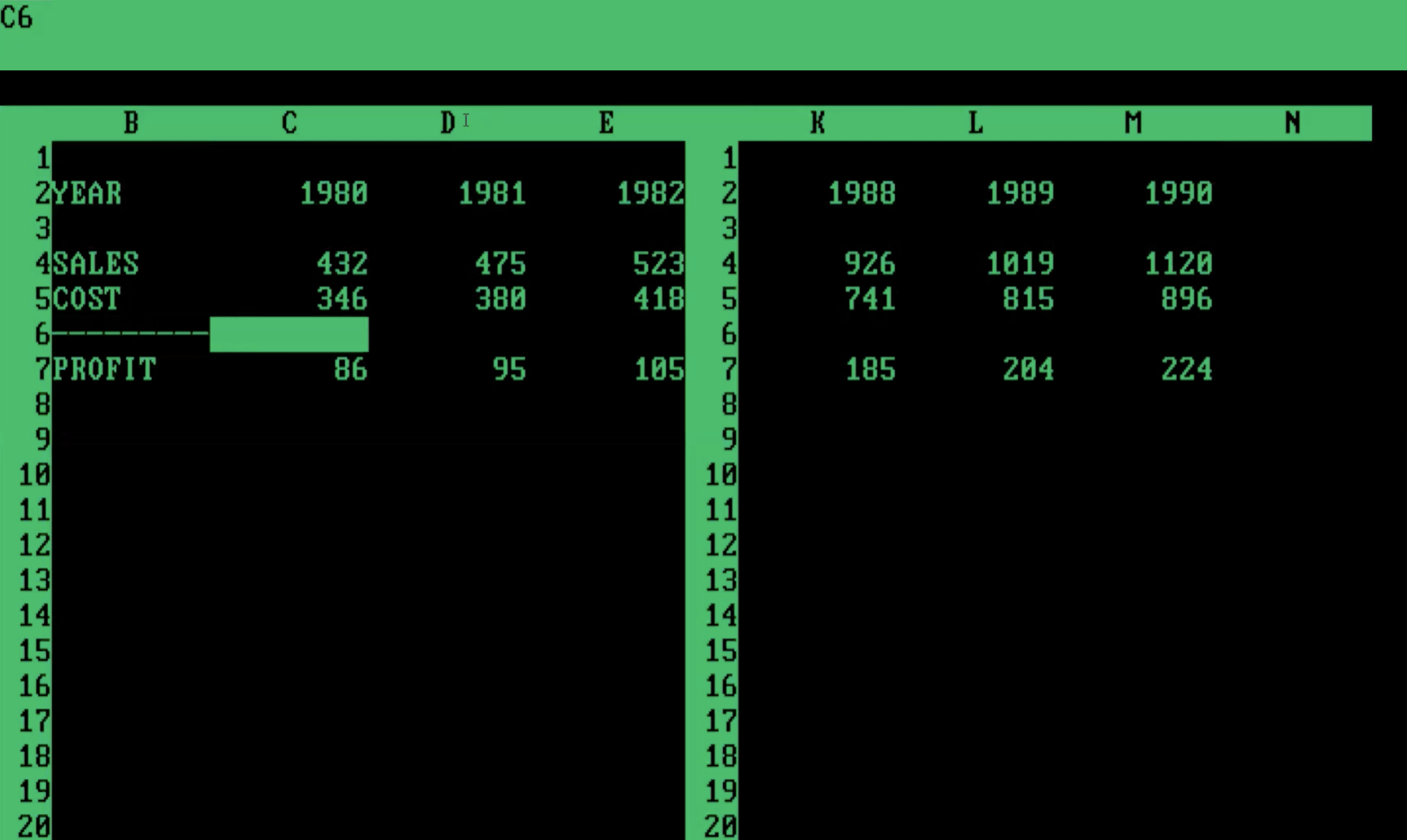
This is a table in VisiCalc (earliest example of a table in a spreadsheet application). It’s pretty crude compared to the tables in print but the advantage here is that you can calculate values quickly.
The grid cells couldn’t be styled with borders for presentation purposes, the values couldn’t be formatted, and the tables couldn’t even be printed. I mean, try it out and you’ll see that this is quite limited in more than a few ways.
Over time, and this took about 10-15 years, tables-within-spreadsheets got a little easier on the eyes. By the early 1990s, Excel could paint borders on your tables, better typographical support was available, and the formatting of values was fully-featured (though, wonky). Great! Problem solved, right? Not really.
While Excel tables from the last three decades looked much better than 1980s-spreadsheet-borne tables, they could never hold a candle to the what was shown in the Census Manual (no matter how much of an Excel expert you became). Further to this, data analysis started to became a thing accomplished outside of Excel. One example of that is Python and its use inside Jupyter notebooks. We now have a bag of problematic scenarios
- all Python: analyze data and generate tables all in Python (bad tables)
- all Excel: analyze data and make tables in Excel (less flexible analysis)
- split-brained: analyze data in Python, copy over to Excel to make tables (not reproducible)
All of these are suboptimal solutions. We propose that it is far better to do everything in Python: the data ingestion, the data analysis, and the data visualization. The visualization step is what’s done for plots and other types of graphics composed from data, it shouldn’t be any different when it comes to generating summary tables.
Approach to tables taken by Great Tables
Great Tables restores the elegance of midcentury tables with the power of a coding interface. With Great Tables anyone can make beautiful tables in Python. Our framework expresses a table as a combination of six independent components. With this framework, you can structure the table, format the values, and style the table. We firmly believe that the methods offered in the package enable people to construct a wide variety of useful tables that work across many disciplines.
You build with Great Tables iteratively, starting off with your table body from code, adding styling, formatting and other components. Here is a schematic that outlines our terminology and depicts how the different table components are related to each other:
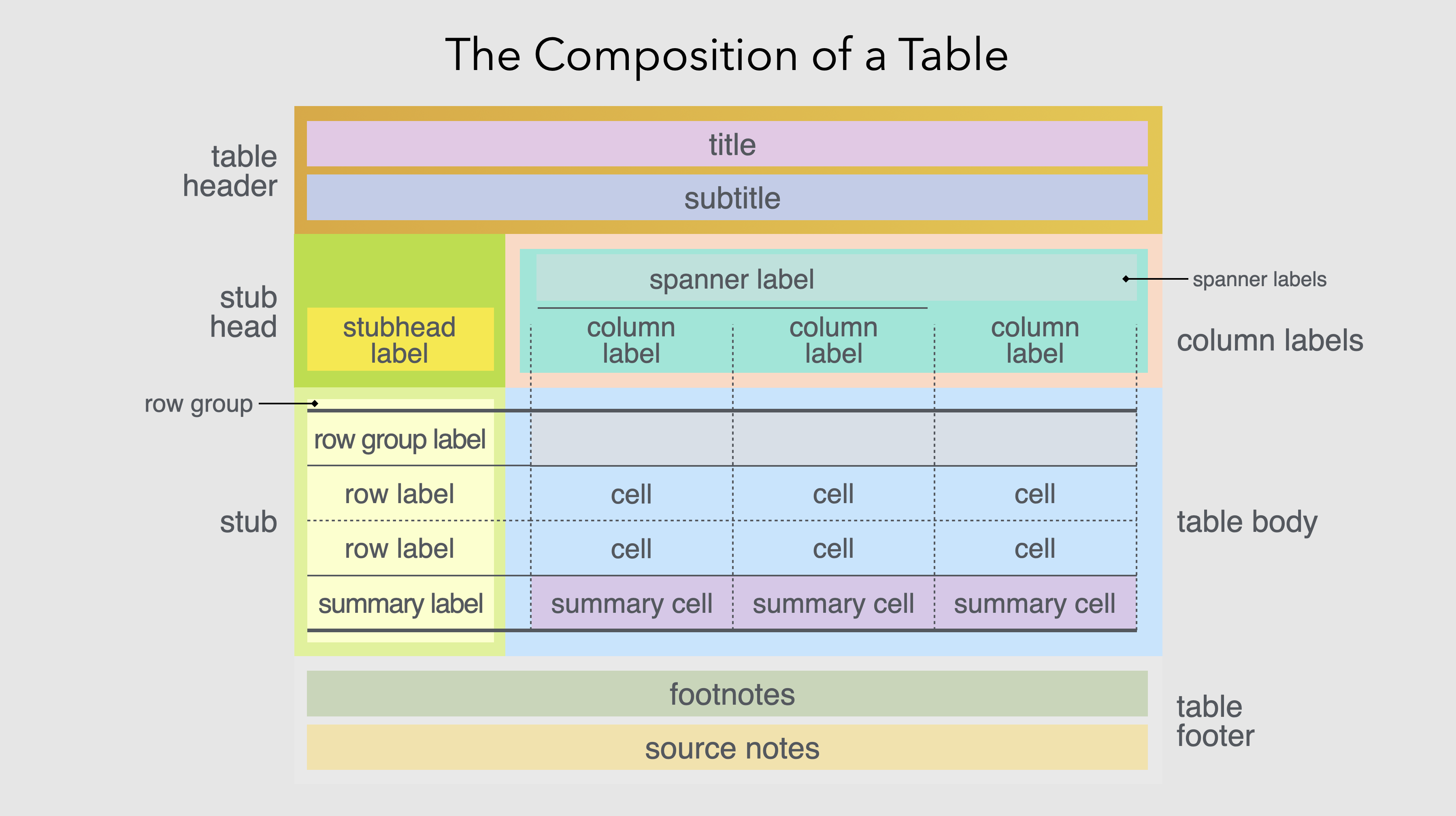
A schematic with the complete set of table components that can be utilized in Great Tables.
Note the following six component pieces:
- Table Header: a place for a title and subtitle, where you can succinctly describe the table content
- Column Labels: the column labels define the content of each column, and spanners are headings over groups of columns
- Stub Head: the ‘top-left’ location, where a label could be used in a variety of ways
- Row Stub: for row information, including row grouping labels
- Table Body: contains cells and so it’s where the data lives
- Table Footer: a place for additional information pertaining to the table content
Here’s a table that takes advantage of the different components available in Great Tables. It contains the names and addresses of people.
Show the code
from great_tables import GT, md, system_fonts
(
GT(simple_table, rowname_col="Name")
.tab_header(title="Names, Addresses, and Characteristics of Remote Correspondents")
.tab_stubhead(label=md("*Name*"))
.tab_spanner(label="Location", columns=["Address", "City", "Postcode"])
.tab_spanner(label="Personal Characteristics", columns=["DOB", "Height", "Weight"])
.tab_source_note(source_note=md("**Data last updated**: December 18, 2022."))
.fmt_date(columns="DOB", date_style="m_day_year")
.fmt_integer(columns="Weight", pattern="{x} lbs")
.opt_stylize()
.opt_align_table_header(align="left")
.opt_vertical_padding(scale=0.75)
.tab_options(
table_font_names=system_fonts(name="rounded-sans"),
table_font_size="14px",
)
)| Names, Addresses, and Characteristics of Remote Correspondents | ||||||
| Name | Location | Personal Characteristics | ||||
|---|---|---|---|---|---|---|
| Address | City | Postcode | DOB | Height | Weight | |
| Dustin B. Roach | 1183 Columbia Road | Holly Oak, DE | 19809 | Sep 16, 1970 | 5' 9" | 202 lbs |
| Iwona Adamczyk | ul. Zabłudowska 133 | Warszawa | 04-788 | Jan 3, 1976 | 5' 5" | 124 lbs |
| Geneviève Massé | 1415 rue Principale | Amos, QC | J9T 1E4 | Dec 8, 1967 | 5' 3" | 136 lbs |
| João Souza Lima | Rua Cosmorama, 538 | São Paulo-SP | 04648-080 | Apr 21, 2001 | 6' 2" | 231 lbs |
| Maddison McCabe | 149 Raymond Street | Strathern | Invercargill 9812 | Mar 5, 1982 | 5' 8" | 146 lbs |
| Data last updated: December 18, 2022. | ||||||
A table of named individuals redone, Great Tables style!
Notice that there is a blue row stub component that makes the row labels distinct from the body of the table. This is important because each person described forms a unique observation and we want to highlight the subject of each row. The heading provides context on what’s contained within the table. The two column spanners arrange the columns into sensible groupings (e.g., ‘Location’). The consistent use of blue lines and cell backgrounds gives the table a professional look.
If you look at the table code above you’ll see that every method for modifying the table starts with tab_. These particular methods are concerned with adding a table component (e.g., tab_header() creates a Table Header) and they’re designed to be easy and straightforward to use.
Formatting
Table structuring is important, but not the only thing. Tables in different disciplines have a certain set of display requirements specific for any values shown. Even something as simple as a number can be formatted in many different ways depending on a community’s norms and expectations. This extends to a very wide area when we consider that dates, times, and currencies also need to be formatted.
Depending on your display requirements, a raw value like 134,000 could presented as:
- scientific notation (
fmt_scientific()): 1.34 × 105 - a number in the German locale (
fmt_number()): 134.000,00 - a compact integer value (
fmt_integer()): 134K
The problem grows worse when values need to be conveyed as images or plots. If you’re a medical analyst, for example, you might need to effectively convey whether test results for a patient are improving or worsening over time. Reading such data as a sequence of numbers across a row can slow interpretation. But by using nanoplots, available as the fmt_nanoplot() formatting method, readers can spot trends right away. Here’s an example that provides test results over a series of days.
Show the code
import great_tables
from great_tables import GT, md
from great_tables.data import illness
import polars as pl
illness_mini = (
pl.from_pandas(illness)
.head(10)
.select(
"test", values=pl.concat_str(pl.exclude("test", "units"), separator=" ", ignore_nulls=True)
)
.slice(1, 9)
)
(
GT(illness_mini, rowname_col="test")
.fmt_nanoplot(columns="values")
.tab_header(md("Partial summary of daily tests<br>performed on YF patient"))
.tab_stubhead(label=md("**Test**"))
.cols_label(values=md("*Progression*"))
.cols_align(align="center", columns="values")
.tab_source_note(source_note="Measurements from Day 3 through to Day 8.")
)| Partial summary of daily tests performed on YF patient |
|
| Test | Progression |
|---|---|
| WBC | |
| Neutrophils | |
| RBC | |
| Hb | |
| PLT | |
| ALT | |
| AST | |
| TBIL | |
| DBIL | |
| Measurements from Day 3 through to Day 8. | |
Notice that if you hover over the data points, you still get values for each of the days. We designed nanoplots to be stripped down plotting visualizations that balance the quick visual interpretation of a plot against the compactness of a table.
Great Tables contains a lot of functionality for formatting. If you peeked at the code in the above table displays you might have noticed there are methods beginning with fmt_ (i.e., fmt_date(), fmt_integer(), fmt_nanoplot()). We want to make many formatting methods available to serve different users’ needs. We also want them to be easy to use, but with many useful options to provide flexibility for all your formatting tasks.
Great Tables is focused on display
There are myriad ways that people interact with tables. Great Tables is focused on the display of tables for publication and presentation. If you’re analyzing data in a database, you might want a simple table display that offers controls to navigate and filter hundreds, thousands, maybe even more records. And that is great for those situations.
The publication of results is a entirely different task, and the emphasis here is on structuring, formatting, and styling. We believe that beautiful table displays should do the following:
- make information easier to digest
- provide extra context wherever needed
- adhere to the style of the document or of the organization
We wanted to help the type of user that wanted to present data in this way. This is typically what you see in journal articles, in books, and in reports. We think the area of static summary tables deserves it’s own focus. This class of tables can look great and we offer various opt_*() methods in the Great Tables API so it’s that much easier to provide a great table to your readers.
In conclusion
Tables have come a long way and we’ve learned a lot from our continued research in tabular design. We hope to make the Great Tables package useful for your generation of summary tables. Given there’s ample room for innovation in this area, we’ll keep plugging away at doing that work to improve the API. We measure success by the quality of the tables the package is able to produce and we always keep that goal top of mind.
We’re very excited about where things are going with Great Tables and we geniunely appreciate community feedback. If ever you want to talk tables with us, you’re always welcome to jump into our Discord Server and drop us a line!
Many thanks to Curtis Kephart and Anthony Baker for providing helpful advice when writing this article.
Footnotes
Taylor, B. (2021). Lunar timekeeping in Upper Paleolithic Cave Art. PRAEHISTORIA New Series, 3(13), 215–232.↩︎
Duke, D. W. (2002). Hipparchus’ Coordinate System. Archive for History of Exact Sciences, 56(5), 427-433.↩︎
Palet, J. M. and Orengo, H. A., The Roman Centuriated Landscape: Conception, Genesis, and Development as Inferred from the Ager Tarraconensis Case. American Journal of Archaeology, 115(3), 383-402.↩︎
Marchese, F. T., Exploring the Origins of Tables for Information Visualization. Proceedings of the 2011 15th International Conference on Information Visualisation, 13-15 July 2011, doi:10.1109/IV.2011.36.↩︎
M. W. Green, The construction and implementation of the cuneiform writing system, Visible Writing, 15, 1981, 345-72.↩︎
Robson, E., “Tables and tabular formatting in Sumer, Babylonia, and Assyria, 2500-50 BCE” in M. Campbell-Kelly, M. Croarken, R.G. Flood, and E. Robson (eds.), The History of Mathematical Tables from Sumer to Spreadsheets. Oxford: Oxford University Press, 2003, 18–47.↩︎
Manual of Tabular Presentation: An Outline of Theory and Practice in the Presentation of Statistical Data in Tables for Publication. United States. Bureau of the Census. U.S. Government Printing Office, 1949. Resource available at: https://www2.census.gov/library/publications/1949/general/tabular-presentation.pdf.↩︎